13th February 2025 - Link Blog
shot-scraper 1.6 with support for HTTP Archives. New release of my shot-scraper CLI tool for taking screenshots and scraping web pages.
The big new feature is HTTP Archive (HAR) support. The new shot-scraper har command can now create an archive of a page and all of its dependents like this:
shot-scraper har https://datasette.io/
This produces a datasette-io.har file (currently 163KB) which is JSON representing the full set of requests used to render that page. Here's a copy of that file. You can visualize that here using ericduran.github.io/chromeHAR.
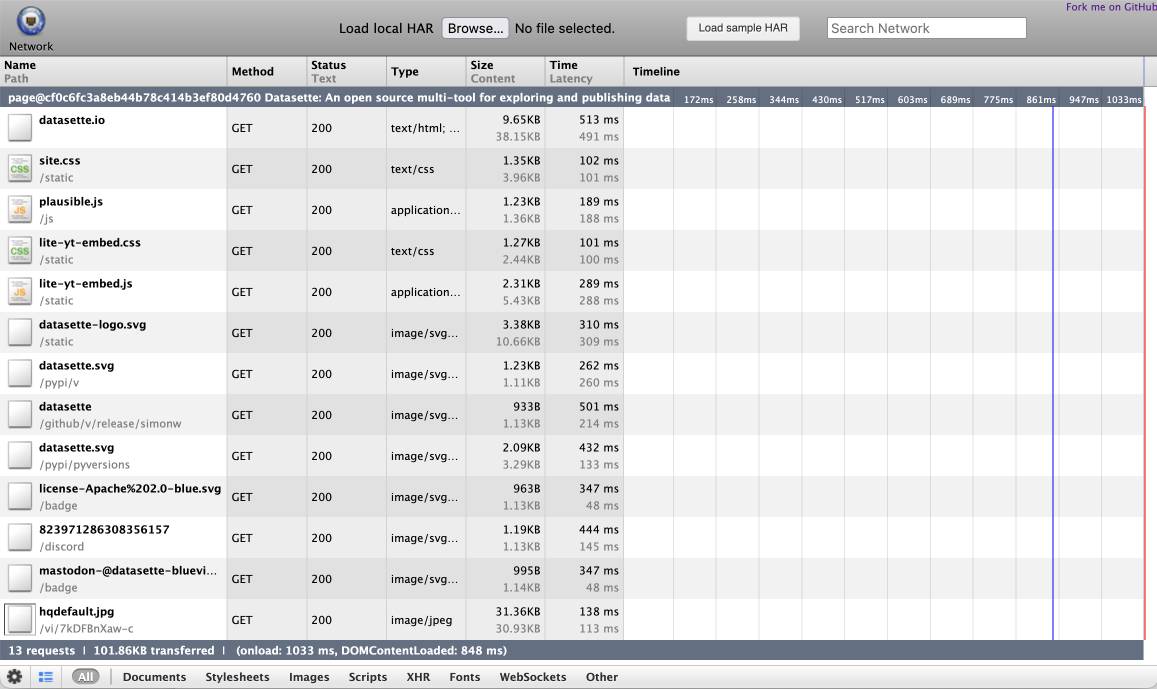
That JSON includes full copies of all of the responses, base64 encoded if they are binary files such as images.
You can add the --zip flag to instead get a datasette-io.har.zip file, containing JSON data in har.har but with the response bodies saved as separate files in that archive.
The shot-scraper multi command lets you run shot-scraper against multiple URLs in sequence, specified using a YAML file. That command now takes a --har option (or --har-zip or --har-file name-of-file), described in the documentation, which will produce a HAR at the same time as taking the screenshots.
Shots are usually defined in YAML that looks like this:
- output: example.com.png
url: http://www.example.com/
- output: w3c.org.png
url: https://www.w3.org/You can now omit the output: keys and generate a HAR file without taking any screenshots at all:
- url: http://www.example.com/
- url: https://www.w3.org/Run like this:
shot-scraper multi shots.yml --har
Which outputs:
Skipping screenshot of 'https://www.example.com/'
Skipping screenshot of 'https://www.w3.org/'
Wrote to HAR file: trace.har
shot-scraper is built on top of Playwright, and the new features use the browser.new_context(record_har_path=...) parameter.
Recent articles
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026
- Profiling Hacker News users based on their comments - 21st March 2026
- Thoughts on OpenAI acquiring Astral and uv/ruff/ty - 19th March 2026