16th April 2025 - Link Blog
Introducing OpenAI o3 and o4-mini. OpenAI are really emphasizing tool use with these:
For the first time, our reasoning models can agentically use and combine every tool within ChatGPT—this includes searching the web, analyzing uploaded files and other data with Python, reasoning deeply about visual inputs, and even generating images. Critically, these models are trained to reason about when and how to use tools to produce detailed and thoughtful answers in the right output formats, typically in under a minute, to solve more complex problems.
I released llm-openai-plugin 0.3 adding support for the two new models:
llm install -U llm-openai-plugin
llm -m openai/o3 "say hi in five languages"
llm -m openai/o4-mini "say hi in five languages"
Here are the pelicans riding bicycles (prompt: Generate an SVG of a pelican riding a bicycle).
o3:
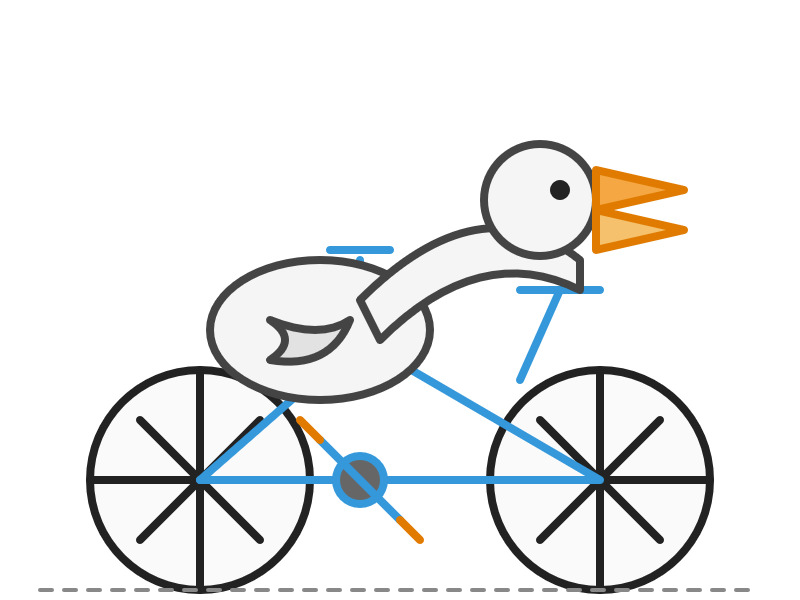
o4-mini:

Here are the full OpenAI model listings: o3 is $10/million input and $40/million for output, with a 75% discount on cached input tokens, 200,000 token context window, 100,000 max output tokens and a May 31st 2024 training cut-off (same as the GPT-4.1 models). It's a bit cheaper than o1 ($15/$60) and a lot cheaper than o1-pro ($150/$600).
o4-mini is priced the same as o3-mini: $1.10/million for input and $4.40/million for output, also with a 75% input caching discount. The size limits and training cut-off are the same as o3.
You can compare these prices with other models using the table on my updated LLM pricing calculator.
A new capability released today is that the OpenAI API can now optionally return reasoning summary text. I've been exploring that in this issue. I believe you have to verify your organization (which may involve a photo ID) in order to use this option - once you have access the easiest way to see the new tokens is using curl like this:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o3",
"input": "why is the sky blue?",
"reasoning": {"summary": "auto"},
"stream": true
}'
This produces a stream of events that includes this new event type:
event: response.reasoning_summary_text.delta
data: {"type": "response.reasoning_summary_text.delta","item_id": "rs_68004320496081918e1e75ddb550d56e0e9a94ce520f0206","output_index": 0,"summary_index": 0,"delta": "**Expl"}
Omit the "stream": true and the response is easier to read and contains this:
{
"output": [
{
"id": "rs_68004edd2150819183789a867a9de671069bc0c439268c95",
"type": "reasoning",
"summary": [
{
"type": "summary_text",
"text": "**Explaining the blue sky**\n\nThe user asks a classic question about why the sky is blue. I'll talk about Rayleigh scattering, where shorter wavelengths of light scatter more than longer ones. This explains how we see blue light spread across the sky! I wonder if the user wants a more scientific or simpler everyday explanation. I'll aim for a straightforward response while keeping it engaging and informative. So, let's break it down!"
}
]
},
{
"id": "msg_68004edf9f5c819188a71a2c40fb9265069bc0c439268c95",
"type": "message",
"status": "completed",
"content": [
{
"type": "output_text",
"annotations": [],
"text": "The short answer ..."
}
]
}
]
}
Recent articles
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026
- Vibe coding SwiftUI apps is a lot of fun - 27th March 2026
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026