OpenAI DevDay 2024 live blog
1st October 2024
I’m at OpenAI DevDay in San Francisco, and I’m trying something new: a live blog, where this entry will be updated with new notes during the event.
See OpenAI DevDay: Let’s build developer tools, not digital God for my notes written after the event, and Building an automatically updating live blog in Django for details about how this live blogging system worked under the hood.
10:19 The keynote is starting with a review of o1, and some examples of applications that use it.
10:30 They started with some demos of o1 being used in applications, and announced that the rate limit for o1 doubled to 10000 RPM (from 5000 RPM) - same as GPT-4 now.
10:31 The first big announcement: a realtime API, providing the ability to use WebSockets to implement voice input and output against their models.
10:33 What can you build with the new realtime API? The demonstrated an updated version of their Wanderlust travel agent demo. The demo uses voice as both input and output.
10:37
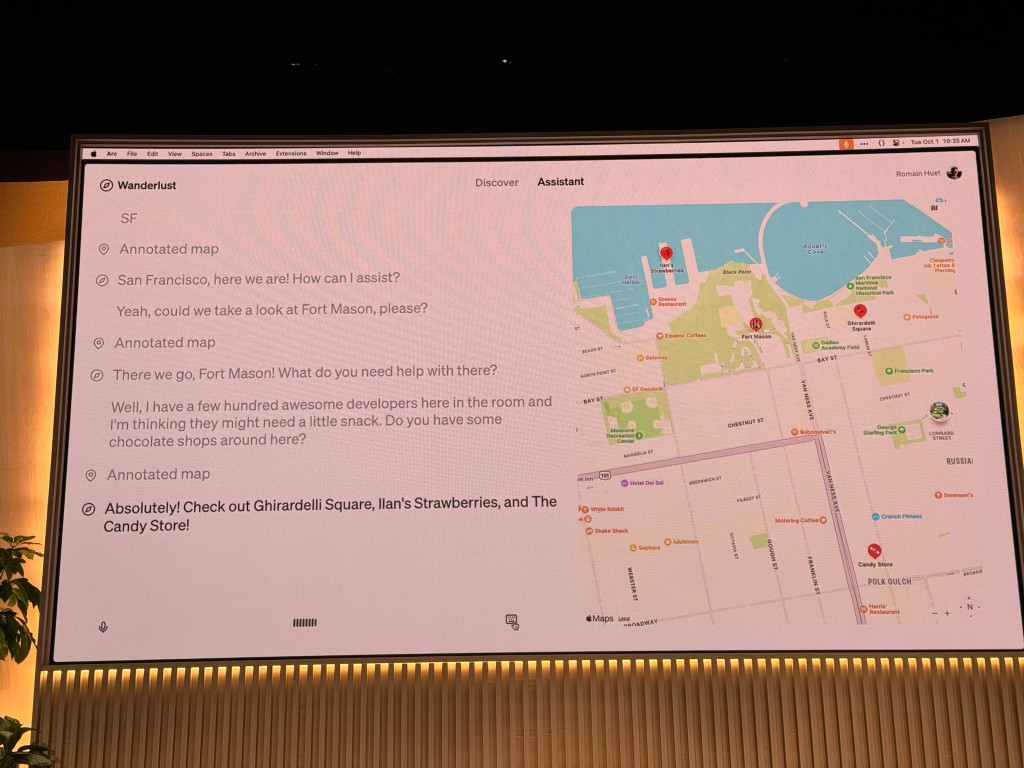
10:39 ... and a demo of an AI assistant making a phone call to order food (thankfully to an OpenAI staff member on stage, not to an actual business!)
10:41 And a demo of the Speak language learning app using the new Realtime API. The API is rolling out generally today.
10:41 Next up: model customization. They have fine-tuning for GPT-4o and 4o-mini now. Today they're announcing fine-tuning support for their vision models.
10:42 Now you can use images to fine-tune the model. They suggest this can be used for product recommendations, medical imaging, or even things like traffic sign detection or lane detection (Grab have been using it for that).
10:42 Fine-tuning with vision is available to every developer for GPT-4 (presumably they mean GPT-4o? Not clear.)
10:43 Next: price drops. Cost-per-token is already 99% cheaper than two years ago.
10:44 Their version of prompt caching is automatic! A 50% discount on tokens the model has seen before.
10:45 Model distillation: where a smaller model is taught by a larger model. Today they're announcing tools for model distillation - so you can fine-tune a 4o-mini model based on output from the larger models.
10:46 Two new tools: stored completions, which lets you store your interactions with the models permanently in the OpenAI platform, to use for fine-tuning and model distillation. That tool ships to all developers today.
10:46 Plus new evaluation tools, also shipping today.
10:47 Sam Altman will be here for the fireside chat in the afternoon, but won't be presenting keynotes before then.
10:51 And now a break. The schedule for the rest of the event has been updated - previously it said "to be announced during the keynote", now we are seeing that 11-11:45am is "Structured Outputs for reliable applications" and 12-12:45pm is "Powerful small models with distillation.
10:52 Then at 2-2:45pm "Multimodel apps with the realtime API.
11:05 Next up: Structured outputs for reliable applications. I've done a bunch of work with the OpenAI tools mechanism in the past for this, most notably my datasette-extract plugin for loading unstructured text and images into structured SQLite database tables.
11:06 Atty Eleti and Michelle Pokrass are talking about structured outputs, the most recent evolution of that mechanism.
11:07 Atty starts with a review of GPT-4 apps like Duolingo, Klarna and Cursor, which "connect to the outside world" - and hence need structured outputs, typically using JSON.
11:08 Classic example of how asking for JSON in the past has often been unreliable - resulting in responses that start "Here is the JSON you asked for...". Developers end up begging for "Just the JSON please!".
11:09 Function calling launched in June 2023, and which helped a bit. In November - last year's DevDay - they released JSON mode that ensured valid data - but this could still hallucinate parameters or output the wrong type.
11:10 Structured Outputs, released in August this year, ensures that the output will exactly match a specified JSON schema. Michelle will explain how this works under the hood. The challenge was making sure the solution was performant for inference at scale.
11:12 Function calling continues to work the same way: you provide a tool with a type of function, then describe that function's parameters using JSON schema. Add "strict": true to that JSON to turn on the new structured output mode for those functions.
11:14 And now a demo, with a function that describes data tables, their columns and operations that can be executed against them. Adding "strict": true fixed a bug where the model used an operator that wasn't defined in the set of operators.
11:15 "response_format": {"type": "json_schema"} enables specifying a full JSON schema that's guaranteed to be followed by the structured outputs mode.
11:17 The demo imagines AI-enhanced glasses, using a neat {"voice_over": "This is what the glasses say to you", "display": "4 feet tall"} output format which updates a display with a short string and specifies a longer string to be spoken out loud.
11:18 Next demo imagines a resume reviewing application, where you can drop a PDF resume directly onto a web form which then uses structured outputs to pull out the fields needed by the resume application.
11:20 The OpenAI library for JavaScript supports Zod for defining these schemas, and the Python library supports Pydantic.
11:21 I'm presuming that previous demo converted the PDF to images automatically - I don't think any of the OpenAI APIs accept PDF directly.
11:23 This next demo is much more interesting: defining a schema for a full dashboard interface, where different cards can represent charts or tables or rows - so now the tool can output a custom answer to a question with embedded charts and data. Hopefully the code will be published on GitHub after the talk.
11:24 Overall this is a pretty sophisticated demo of a custom chat UI with a whole assortment of custom tools built on top of function calling and structured output.
11:25 Atty emphasizes that prior to structured outputs reliability was a really big problem - any of these steps failing could break the entire application.
11:25 Next, Michelle is talking about the underlying implementation of structured outputs.
11:26 "We took an approach that combined both research and engineering". It's more than just prompting - they used a technique called "constrained decoding". (Sounds to me like the Llama.cpp grammars trick).
11:27 As an example, consider handwritten number recognition - where there are only ten possible output labels, from 0 to 9. This is a classic machine learning image recognition task.
11:28 LLMs predict more than just digits through 0-9 - they output tokens, see my article Understanding GPT tokenizers from last year.
11:30 For structured outputs, the trick is to limit which tokens can be produced next. The technique used here is called "token masking". The LLM still generates probabilities for likely next tokens, but they then mask out any tokens that would not match the desired schema.
11:31 These masks have to be updated on every single inference step, so the operation has to be lightning fast to keep inference as fast as possible. Token sampling happens on a GPU in batches - which means the CPU can calculate the masks for the next step in parallel while the GPU is calculating probabilities.
11:32 These masks need to be calculated within 10ms. "We wanted to pre-compute as much work as possible" - to make mask computation more of a lookup. They build an index, derived from the JSON schema, to make fetching those masks as fast as possible.
11:33 JSON Schema is converted into a grammar, then a parser, then they iterate over ALL tokens and parse states and use that to create the index.
11:33 The indexs is a trie - a prefix-based data structure allowing for O1 lookups.
11:34 Generating the index is computationally expensive due to the need to go over all of the possible states. They do that just once and cache the index - which is why the first query to structured inputs can take a little time - sometimes up to 10 seconds - but following prompts are fast.
11:35 The open source community has used tricks to implement masks by turning a schema into a regular expression. But regular expressions don't cover recursive or deeply nested schemas - so they can't cover all of the features of JSON Schema.
11:35 Generative UI is a good example of a use-case that needs nested schemas - each component can have a list of children that might include more components. These cannot be converted to a regular expression due to that limit in terms of recursive nesting.
11:37 OpenAI wanted recursive JSON schema support, so they added a stack. They call this the CFG - Context Free Grammar - approach, which combines regular expressions and a stack. This is why it takes a little bit of time to build up the trie for inference.
11:38 So the trade-off here is the short delay when the schema is first encountered, which OpenAI think is worthwhile for the improved reliability.
11:38 Atty is now talking about the research side: how can we get the model to follow the schema in the most useful way possible?
11:39 If you force a model to output JSON fitting the grammar, you might end up with {\n\n\n\n\n\n\n\n\n\n\n\n until it hits the maximum of tokens.
11:40 OpenAI's internal evals showed that gpt-4o-2024-08-06 with Structured Outputs was far more accurate than prompting alone against the older models. They now get to 100% on that eval (not sure what that's measuring though).
11:42 One of the controversial API design decisions made was around additionalProperties: true - which is usually a default in JSON Schema. OpenAI have disallowed additional properties by default in their API, which differs from developer expectations.
11:42 OpenAI say explicit is better, so developers have to pass additionalProperties: false in their schemas.
11:43 All properties are required by default - no support for optional parameters (although they can be made nullable). Developers need to follow this rule in the JSON Schemas they send over as well.
11:43 Fields are generated in the same order that you defined them in the schema, even though JSON is supposed to ignore key order. This ensures you can implement things like chain-of-thought by adding those keys in the correct order in your schema design.
11:45 Looks like the documentation for the new Realtime API is now available.
11:46 This session didn't present any new features - they were all in the documentation already - but the insight into how the Structured Output works under the hood was new.
12:01 Next up: Powerful small models with distillation, with John Allard and Steven Heidel.
12:02 Distillation "allows you to create powerful, small models". They'll talk about why it matters, how it works and best practices and use cases - plus demos of the two new API platform features they are launching today.
12:02 Once you get an AI app working, the next step is figuring out how to get it to work at scale. You care about uptime, rate limits, latency and cost.
12:04 GPT-4o is 15x more expensive than GPT-4o mini, but it brings a large amount of additional "knowledge" - graduate level physics etc. It excels at the toughest knowledge benchmarks. Do you need that type of intelligence for your application?
12:06 Distillation: you fine-tune the small output on the outputs of the large model. You're compressing some of the capabilities of the large model into that smaller model.
12:07 Distillation involves three steps. The first and most important is to build task-specific evals for your application. You can't skip this step, because you can't improve what you can't measure.
12:07 The second step is to capture examples of what good performance looks like. Store example completions from a large model like GPT-4o and create a dataset.
12:08 The final step is the fine-tuning. Teach the small model how to replicate the responses from the large model by showing it many of those captured examples. We're trying to "compress the intelligence" of the large model into that small model.
12:09 A lot of people have done distillation on the OpenAI platform before, using the existing fine-tuning mechanism. Doing it that way is a lot of work though.
12:10 The two new features they are launching today will make distillation easier. The first is stored completions: a new parameter to the chat completions API that will let you opt-in to storing the full input and output to the model. You can apply tags as well, to help filter those later to create datasets for fine-tuning. {"store:" true}
12:11 The second feature is a beta of an Evals product. This should allow you to do distillation end-to-end on the OpenAI platform.
12:11 Real-world use-case based on the Superhuman email app. That app has a "quick reply" feature that suggests options for a reply based on reading through the existing thread. How would you scale that feature to hundreds of millions of emails?
12:13 Aside: here's openai/openai-realtime-api-beta with example code for talking to the new Realtime API using JavaScript. openai/openai-realtime-console is an example React app.
12:14 Using the Python client library for client.chat.completions.create() you can add store=True, metadata={"tag": "test-set"} to store a prompt/response and add it to a tag.
12:14 A new UI at platform.openai.com/chat-completions lets you browse through your stored completions.
12:15 Then in the new /evalutions/create interface you can add testing criteria and use that to create a new evaluation. (I don't have access to that page yet.)
12:17 Having created an eval it's easy to run that against other models - try it against GPT-4o mini and compare that with GPT-4o for example.
12:20
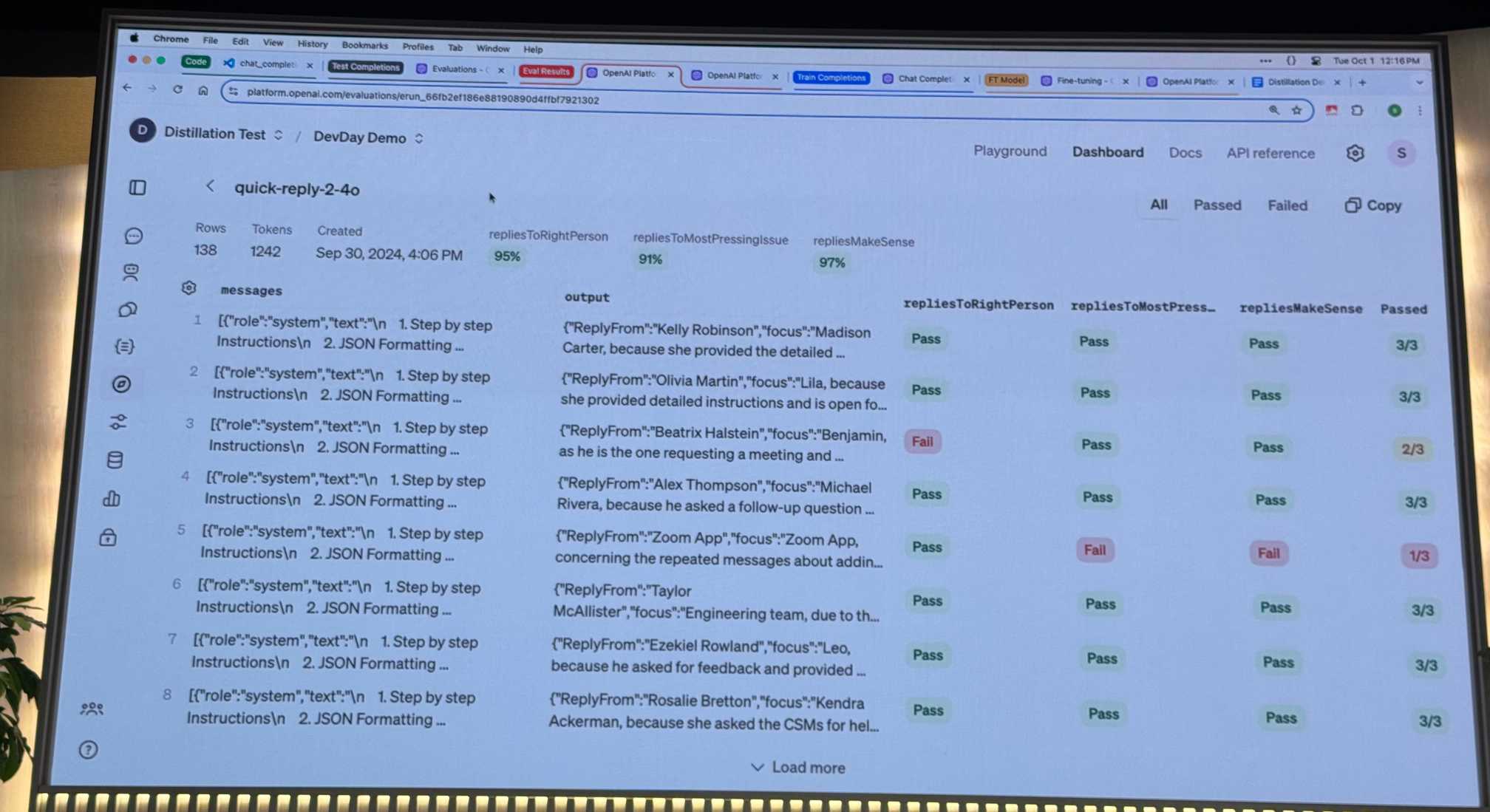
12:21 ... and now a demonstration of the fine-tuning UI, showing how a fine-tuned GPT-4o mini model on that data performs much better than 4o-mini on its own.
12:23 Is distillation right for your use-cases? That comes down to task generality against required precision. Great use-cases for distillation are tasks that cover a relatively narrow domain and have a relatively low precision requirement - a great fit for small models.
12:23 Tasks that have high precision needs but narrow generality work well too - that's a lot of forms of categorization. You may need a larger and more diverse data set to get that to work well. Same for broad generality and low precision.
12:24 Tasks with a broad generality and high need for precision are a poor fit for distillation - they need a full-powered large model.
12:25 Things to watch out for: Unevenly distributed or biased data points. Your training data should match the patterns of your production data. Also sparse examples which may result in blind spots in your data. A great example is fraud - if it's rare you might find that 1,000 samples have no instances of fraud at all!
12:26 Part of the value of distillation is you don't necessarily need human generated data or responses - but that doesn't mean you don't need to actively curate your distillation dataset. "We tend to see distillation work best with the order of thousands rather than millions of examples."
12:27 Finally, take an iterative approach. Fine-tuning might not work on your first try - there are many variables to consider. It's important to start small with a few hundred examples and scale up once you know it's working based on your evals. Don't jump straight to millions of data points.
12:28 It strikes me that fine-tuning and distillation are strategically a great way of keeping people locked to one platform - if you build an application purely on top of prompt engineering it's much easier to swap between different LLM vendors than if you have fine-tuned a model.
12:29 They expect that it will become common for applications to be built using a collection of many different distilled small models, with a few large models for tasks that don't work well for distillation.
12:30 ... and now lunch - sessions resume at 2pm.
12:32 The system I built for this live blog is very simple - just fetch() calls polling an endpoint and updating a <div> using innerHTML - but the endpoint itself sets a 10s cache so Cloudflare should only let a hit through to the underlying app every 10s no matter how many people are viewing the page.
13:27 I've upgraded this live blog (with the help of GPT-4o) - it no longer refreshes the entire updates section (since that means any selected text is un-selected), instead appending new updates to the existing HTML. I've also added a toggle to switch between a display order of most-recent or least-recent first.
14:01 Multimodel apps with the Realtime API - Jordan Sitkin, API Capabilities and Katia Gil Guzman, Developer Experience
14:04 Building multimodal apps right now involves wiring together several different components: Whisper, then GPT-4, then a TTS model for output. This makes it hard to build "fluid conversational experiences that feel life-like".
14:04 The new Realtime API means GPT-4o can handle all of this as a single component - audio input, processing and then audio output.
14:06 The focus for this first release of the Realtime API is speech, text and function calling.
14:08 First, a demo of an app built the old way - with Whisper and then GPT-4 and then TTS output. It's clearly not real-time enough for the experience to be worthwhile.
14:08 Next a demo of the Realtime API, which feels much more responsive. It's effectively the same experience as using the ChatGPT app with the new voice mode.
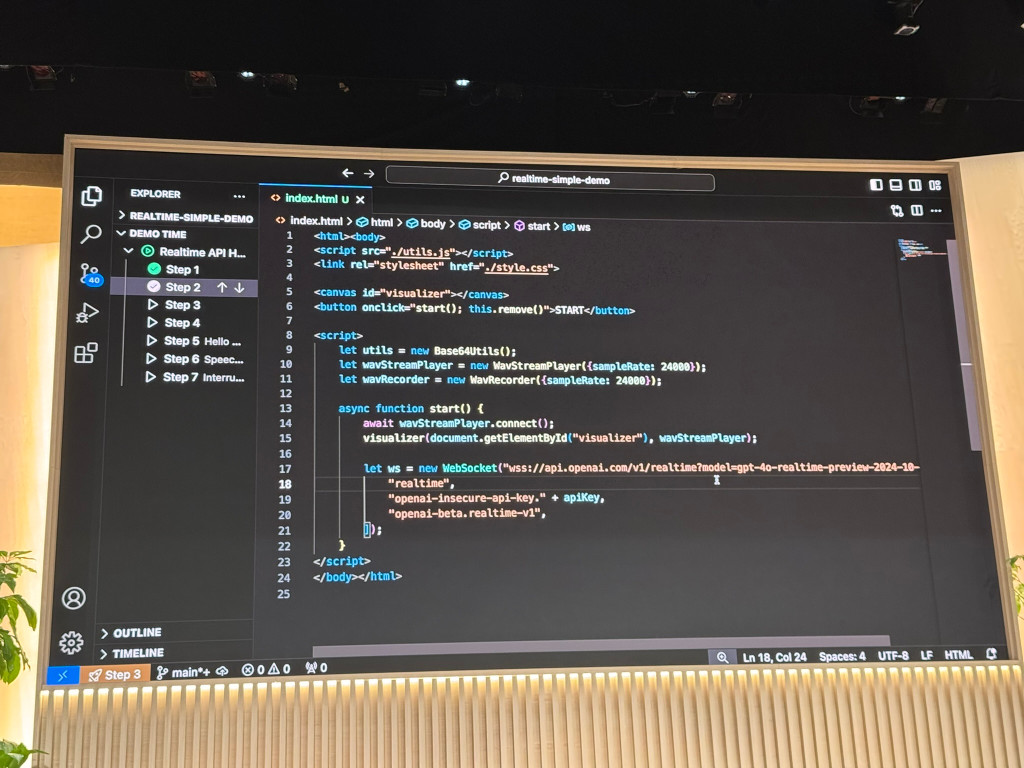
14:10 The Realtime API exposes a new endpoint that provides a WebSockets connection for your application. You can exchange JSON messages containing a mix of text, audio and function calls.
14:13 The example code demonstrates connecting directly to the API with a WebSocket, though that's not recommended for most apps as it exposes the OpenAI API key in the source code. Audio data is encoded is base64 and sent as JSON.
14:14
14:16 It's also possible to implement interruptions using the API.
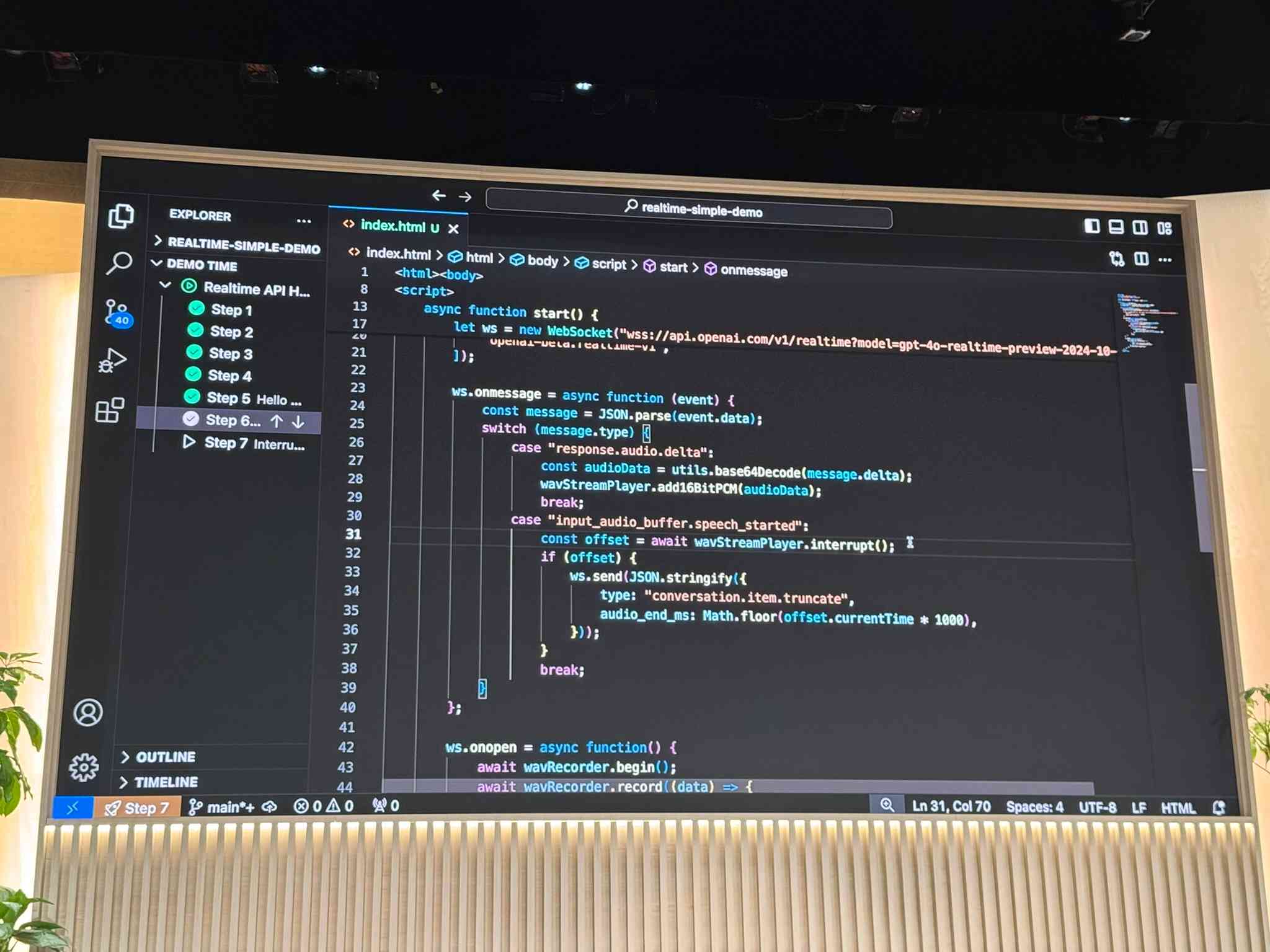
14:17 It's very neat that it's possible to connect to the API and implement full voice mode using just Vanilla JavaScript with no extra dependencies (albeit with an exposed API key) - but that's not how most implementations are likely to work.
14:19 Katia used o1 to help build a 3D visualization of the solar system, then added voice mode to answer questions like "how many planets are there in the solar system" (it tried and failed to display a bar chart, which was unintended and didn't quite work). Then "I'm curious about Earth" caused the visualization to zoom in on Earth while speaking out loud about the planet.
14:20 This is a very cool demo.
14:21 It's using a display_data tool for additional rendering of charts on the visualization.
14:21
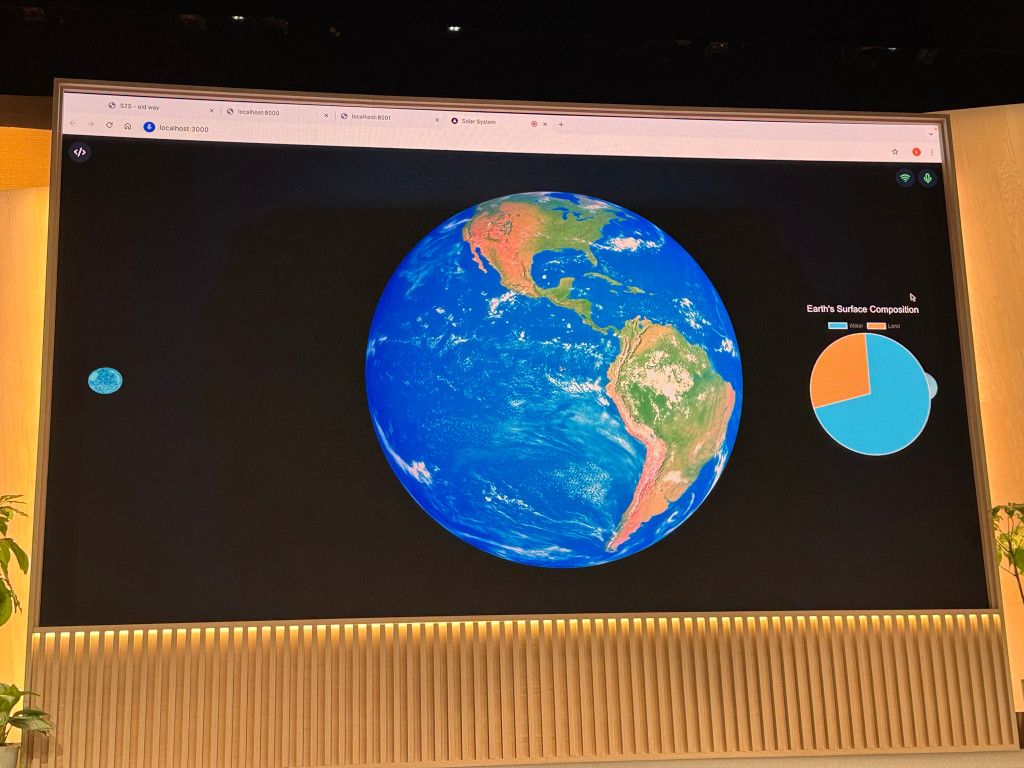
14:22 One more demo, this time "Where is the ISS right now" could rotate Earth to show the ISS, based on a function call that retrieves the real current position of the ISS.
14:24 And a neat little show_moons() tool which zooms in on a planet and highlights its moons.
14:26 The Realtime API starts in public beta today, and is currently rolling out. It's going to be $5/1m tokens for input and ... I missed the rest of the pricing, they skipped the slide forward.
14:26 S2S = Speech to Speech.
14:28 Pricing is up on the pricing page. $5/m input and $20/m autput for text, $100/m input and $200/m output for audio. A note says that "Audio input costs approximately 6¢ per minute; Audio output costs approximately 24¢ per minute".
14:30 Various attendees at DevDay have tried and failed to access the Realtime API (myself included) - from talking to OpenAI staff it sounds like it's still rolling out.
14:42 I'm switching tracks - I'm now in OpenAI Research: Building with o1 with Jason Wei and Hyung Won Chung (starting in 18 minutes).
14:43 Here's what my live blogging interface looks like - I use the Django admin to add new "live update" items attached to an entry, which show up on the entry page a few seconds later.
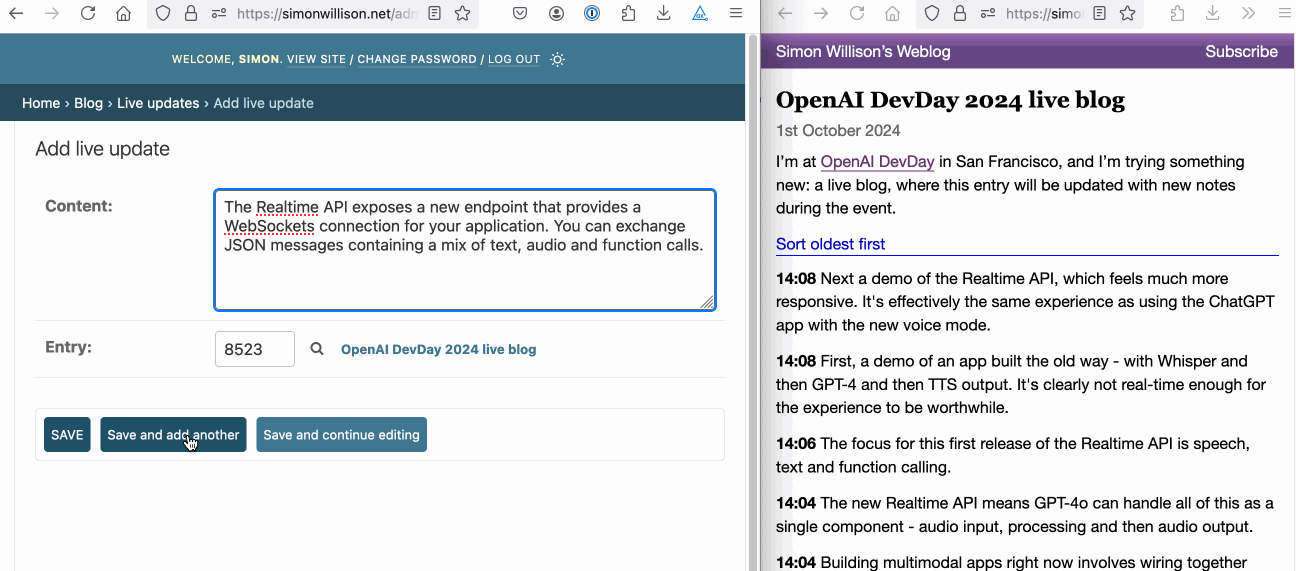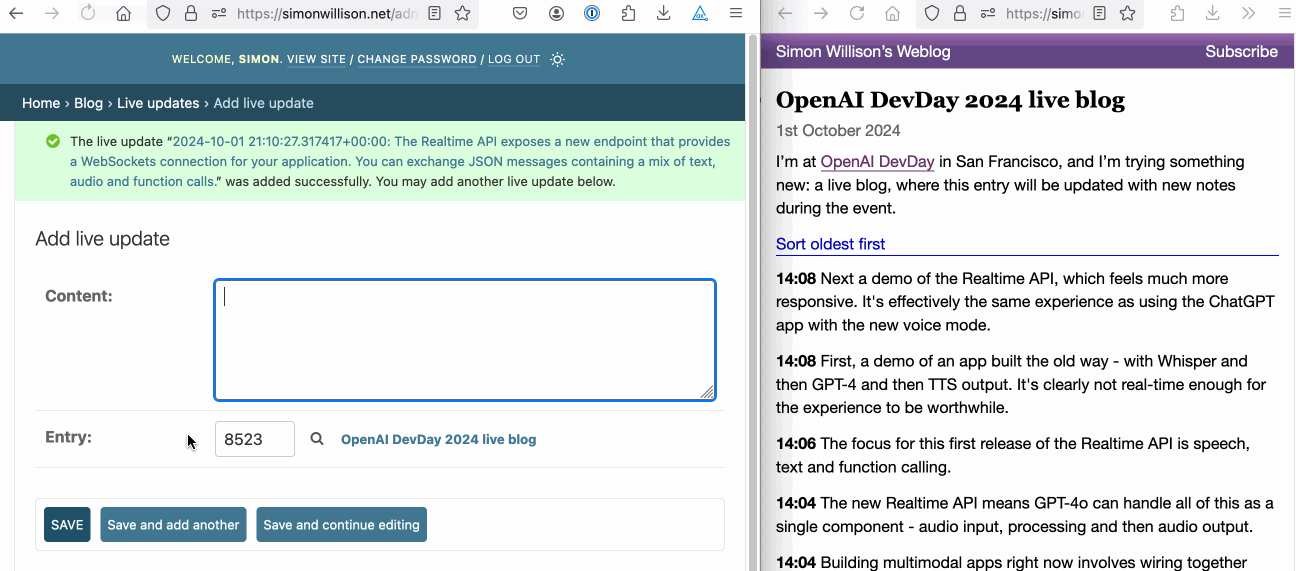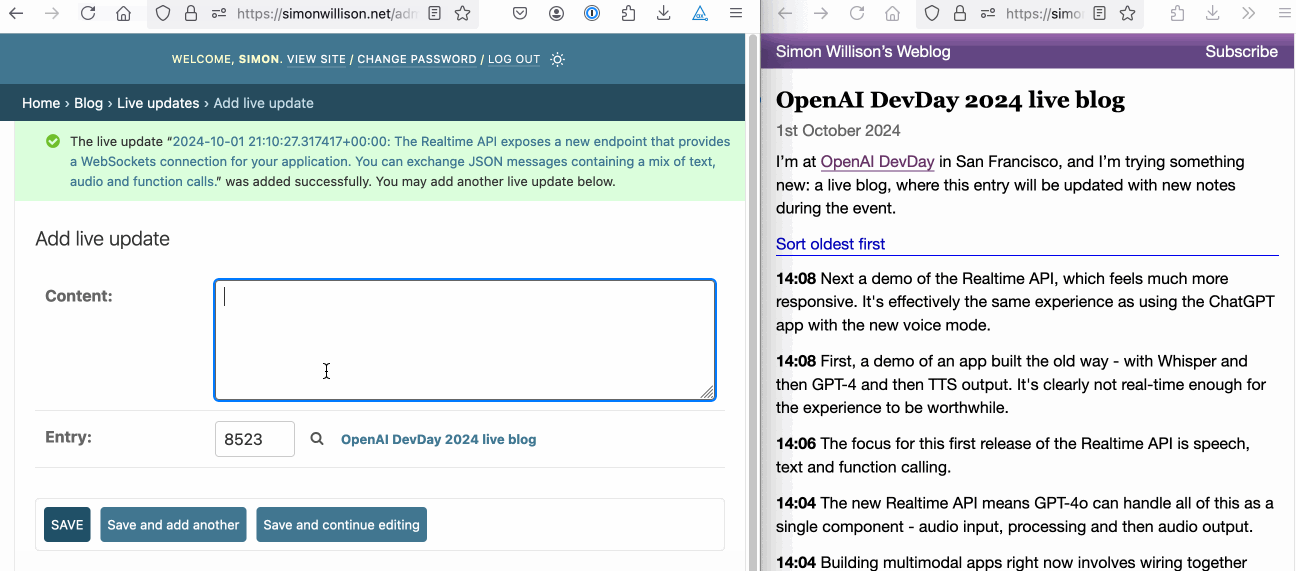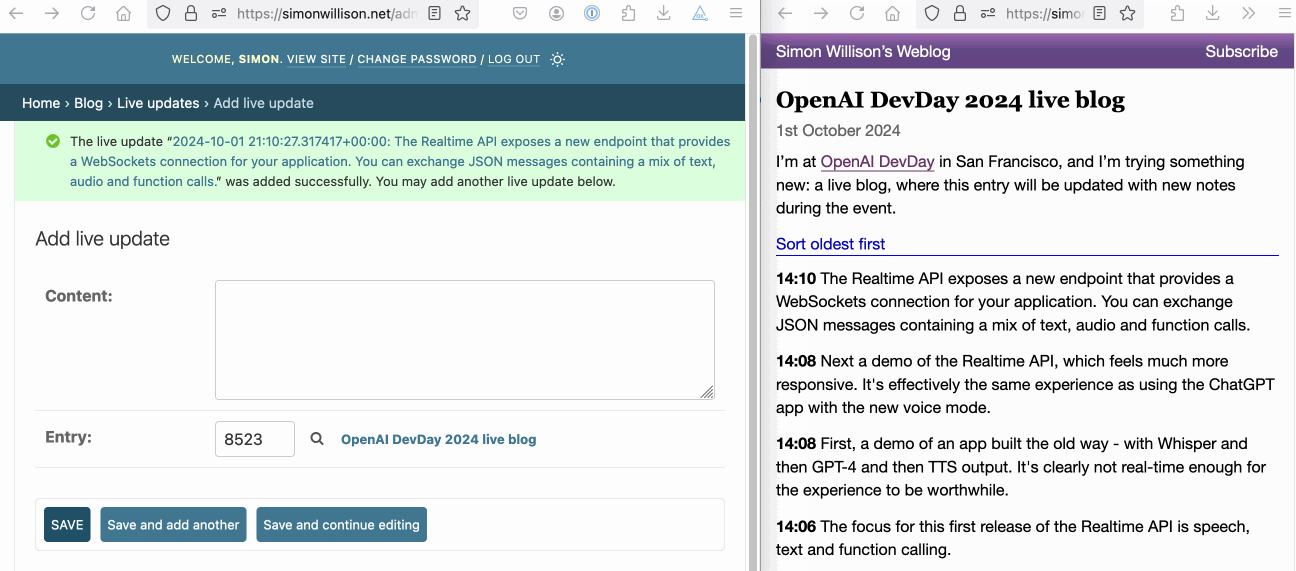
15:00 Hah, only just noticed that this live blog has been up on Hacker News for the last four hours!
15:01 Members of the o1 research team are going to be talking to us about how we should be thinking about using o1. I've been finding it really hard to develop intuition as to what kind of problems are best handled by o1 so I'm looking forward to this.
15:01 First, Tilde Thurium from Launch Darkly is talking about Social justice and prompt engineering.
15:02 Evaluating and Mitigating Discrimination in Language Model Decisions is a paper from Anthropic investigating if Claude 2.0 showed bias while making high-stakes decisions about human beings. Key lesson: you should not use LLMs to make high-stakes decisions about human beings!
15:04 Researchers tried putting demographic data in directly, and also tried hiding the demographic data but using names that hinted at demographics. Claude expressed positive discrimination towards minority groups but negative discrimination towards people over 65. They did find that prompts to remind Claude not to discriminate were actually moderately helpful!
15:05 That Anthropic paper includes published prompts and responses.
15:05 Second paper: Measuring Implicit Bias in Explicitly Unbiased Large Language Models
15:06 Asking models to make explicit yes/no decisions appears to expose less bias than trying to get models to e.g. rank candidates.
15:07 "Kelly is a Warm Person, Joseph is a Role Model": Gender Biases in LLM-Generated Reference Letters. Tilde thinks we can improve on the prompt used in that paper.
15:09 LaunchDarkly: Introducing AI Model and AI Prompt Flags - features for running these kinds of experiments.
15:10 Now: OpenAI Research: Building with o1 with Jason Wei and Hyung Won Chung from the o1 research team.
15:11 o1 is a "reasoning model" - it's been trained to think with reinforcement learning. It's been taught to "refine its thinking strategies" and "recognize and correct its mistakes".
15:13 Given this new model, what changes? What becomes possible with o1 right now and what will become possible with future versions of o1?
15:14 Future versions of o1 should be easy to think about: reasoning will become better. What would you want to build if reasoning is 50% better? (I hope they define "reasoning", I'm never entirely clear what people mean by that term.)
15:15 They're using the word "paradigm" a lot!
15:17 There is a subset of math and code tasks where GPT-4o struggles, but o1 (and o1 preview) handle them much better. The Learning to Reason with LLMs blog post is being referenced a lot for examples.
15:19 o1-mini is recommended over o1 preview for math and coding.
15:20

15:22 The key thing to understand about o1 is that it allows us to trade additional time and processing power for higher quality answers.
15:24

15:25 More documentation for features announced today: Introducing vision to the fine-tuning API, Prompt Caching in the API and Model Distillation in the API.
15:27 Now waiting for the last session of the day, the 4pm fireside chat with San Altman and Kevin Weil.
15:42 I just chatted with an OpenAI staff member about the Realtime API. It doesn’t have image input support yet but that’s planned - so right now it can only do text and audio. The hardest part of using it is going to be rigging up a Websocket proxy to avoid exposing an API key to end users - I said the feature I want most now is for OpenAI to handle that proxy for me, since that’s the most involved part of getting this stuff into production.
15:44 I also asked about sending larger blocks of audio at once - I’d personally like to use this new mechanism outside of realtime as a way to input longer audio directly to GPT-4o. The current expectation is for buffered audio to be sent over the Websocket multiple times per second.
16:00 Last session of the day: Fireside chat with OpenAI leaders
16:04 From the Prompt Caching article:
API calls to supported models will automatically benefit from Prompt Caching on prompts longer than 1,024 tokens. The API caches the longest prefix of a prompt that has been previously computed, starting at 1,024 tokens and increasing in 128-token increments. If you reuse prompts with common prefixes, we will automatically apply the Prompt Caching discount without requiring you to make any changes to your API integration. [...]
Caches are typically cleared after 5-10 minutes of inactivity and are always removed within one hour of the cache's last use
16:06 Here's the documentation for the new evals tool, including screenshots of the interface.
16:09 It's interesting to note that OpenAI prompt caching is a 50% discount that is applied automatically, while Claude's prompt caching is a 90% discount but you have to manually decide where your caching cut-off should be.
16:09 Fireside chat is kicking off now. Here are Sam and Kevin.
16:11 (Kevin Weil is OpenAI's new Chief Product Officer, he joined in June this year.)
16:13 Opening question to Sam: how close are we to AGI? Sam says they're trying to avoid the term now because it has become so over-loaded. Instead they think about their new five steps framework.
16:13 "I feel a little bit less certain on that" with respect to the idea that an AGI will make a new scientific discovery.
16:14 Kevin: "There used to be this idea of AGI as a binary thing [...] I don't think that's how think about it any more".
16:15 Sam: Most people looking back in history won't agree when AGI happened. The turing test wooshed past and nobody cared.
16:16 Sam: There was a time in our history when the right thing to do was just to scale up compute. Right now the answer is to really push on research - o1 was a giant research breakthrough that we were attacking on many vectors for a long time.
16:17 Sam: To do something new for the first time - to really do research in the true sense of it. Let's go find a new paradigm - that's what motivates us. We know how to run that kind of culture that can push back a frontier. "We only have to do that a few more times and then we get to AGI".
16:18 Kevin: Building product at OpenAI is fundamentally different from any other organization I've worked at. Usually you understand what your tech stack is and how to use it, and you can then ask how to use that to build a new product. At OpenAI the state of what computers can do evolves every 2-3 months, and then computers have a new capability that they never had in the history of the world.
16:18 (I'm paraphrasing what they're saying here, and trying to put exact quotes in quotation marks.)
16:19 Sam: "We have guesses about where things are going to go - sometimes we're right, often we're not". Our willingness to pivot everything when something starts working is important.
16:19 Kevin: An enterprise said they wanted 60 days notice in advance of when you're going to launch something, "I want that too!"
16:20 Question: Many in the alignment community are worried OpenAI are only paying lip-service to alignment. Can you reassure us?
16:20 Sam: "We really do care a lot about building safe systems. We have an approach to doing it which has been informed by our experience so far. [...] We want to figure out how to build capable models that get safer and safer over time."
16:21 Sam: "We have an approach of: figure out where the capabilities are going, then work to make that system safe. o1 is our most capable model ever but it's also our most aligned model ever."
16:22 Sam: "We have to build models that are generally accepted as safe and robust in order to put them in the world." What they thought would be important when they started OpenAI turned out not to be anything like the problems they actually need to solve.
16:22 Sam: "I think worrying about the sci-fi ways that this all goes wrong is also very important. We have people thinking about that."
16:23 Kevin: "I really like our philosophy of iterative deployment. When I was at Twitter back a hundred years ago Ev said "No matter how many smart people you have inside your walls, there are way more smart people outside your walls". [...] Launching iteratively and launching carefully is a big way we get these things right."
16:24 Question: How do you see agents fitting into OpenAI's long-term plans?
16:24 Kevin: "I think 2025 is really going to be the year that this goes big".
16:26 Sam: "Chat interfaces are big and have an important place in the world. But when you can ask ChatGPT or some agent something and you don't get a quick response or 15s of o1 thinking but you can really give something a multi-turn interaction with environments and people" ... and have it perform the equivalent of multiple human days of work. "People get used to any new piece of technology quickly" but this will be a very big change to how the world works in a short space of time.
16:27 Sam: "I think people will ask an agent to do something for them that would have taken them a month, and it takes an hour - and then they'll have ten of those at a time, and then a thousand at a time - and we'll look back and say that this is what a human is meant to be capable of."
16:27 Sam: The great thing about having a developer platform is "Getting to watch the unbelievable speed and creativity of people who are building these experiences."
16:28 Question: What do you see as the current hurdles for computer-controlling agents?
16:29 Sam: Safety and alignment. "If you're going to give an agent the ability to click around on your computer you are going to have a very high bar for the robustness ad alignment of that system." (Sounds to me like we need to solve prompt injection and related issues.)
16:30 Sam "If you are trying to get o1 to say something offensive, it should follow the instructions of its user most of the time." - they start very conservative and then relax things over time.
16:31 Question: What's the next big challenge for a startup using AI as a feature?
16:32 Kevin: We face this too. Trying to find the frontier - these AI models are evolving so rapidly, if you're building for something the model does well today it's going to feel old tomorrow! You want to build for something the AI model can just barely not do, so when the next model comes out you'll be the first to do it and it's going to be amazing.
16:32 Sam: "It's tempting to think that a technology makes a startup, and that's almost never true, no matter how cool the new technology is. It doesn't excuse you from doing all of the hard work to build a great company that's going to have durability and advantage over time."
16:33 "In the unbelievable excitement and updraft of AI, people are inclined to forget that."
16:34 Sam: Voice mode was the first time I had gotten tricked by an AI - the first time I was playing with it I couldn't stop myself. I still say please to ChatGPT, but I really felt that with voice mode - and I still do.
16:35 Sam: "As these systems become more and more capable, and we try to make them as natural as possible to interact with, they're going to hit parts of our neuro-circuitry..." - which points at the kinds of safety and alignment issues we need to pay attention to.
16:35 When is o1 going to support function calls? Kevin: "Before the end of the year." (Applause).
16:36 o1 is going to get system prompts, structured outputs and function calling by the end of the year.
16:36 Sam: "The model (o1) is going to get so much better so fast [...] Maybe this is the GPT-2 moment, we know how to get it to GPT-4". So plan for the model to get rapidly smarter.
16:37 Question: What feature of a competitor do you really admire?
16:37 Sam: "I think Google's NotebookLM is really cool [...] it's a good, cool thing. Not enough of the world is shipping new and different things. That brought me a lot of joy this morning, it's very well done."
16:38 Kevin: "They nailed the podcast style voices. They have really nice microphones, sonorous voices." Kevin references the idea of getting it to read your LinkedIn profile and say nice things about you.
16:38 Sam appreciates the design of Claude projects.
16:39 Question: How do you balance what users think they may need v.s. what they actually need?
16:40 Kevin: It's a real balance when we have 200 million people to support every week. But think of the majority of the world who have never used any of these products. You're giving them a text interface, and on the other side of that text interface is this alien intelligence ... and you're trying to teach them all of the things they can do with it. "And people don't know what to do with it, so they come in and type hi" - and they then don't see the magic in it. "Teaching people what those things can be, and bringing them along as the model changes month by month and gains new capabilities [...] it's a really interesting set of problems."
16:41 Sam asks if people who spend time with o1 feel like they're "definitively smarter" than that thing, and if they expect to feel that way about o2.
16:42 Sam: "It has definitely been an evolution for us to not be entirely research focused, to fix all of these bugs and make this stuff useful".
16:43 How many people say "please" and "thank you" to the models? Sam and Kevin and many hands around the room.
16:43 Question: Do you plan to build models specifically aimed at agentic use-cases?
16:43 Sam: "Specifically" is a hard thing to ask for, because things like tool use and function calling and reasoning are things we want to build into all of our models.
16:44 Question: How extensively do you dog-food your own technology in your company, and do you have any non-obvious examples?
16:44 Sam: We put up internal checkpoints and have people use them however they can. We're still always surprised at the creativity of the outside world. "The way we have figured out every step along the way of what to push on next is by internal dog-fooding."
16:45 Sam: "We don't yet have employees that are based on o1, but as we move into the world of agents we will try that."
16:45 Kevin: The customer service team is 20% the size it might otherwise be thanks to model automation. The security team do a lot of work with models to replace manual processes, have models separate signal from noise and highlight to humans what they should go and look at.
16:46 Question: Do you have plans to let people share models for offline usage, especially with distillation?
16:47 Sam: We're open to it, but it's not a priority. There are plenty of reasons you might want a local model, but it's not a "this year" kind of thing.
16:47 Question: Once AGI is achieved are there plans to work with governments? For solving world hunger etc.
16:48 Kevin: You want to start now. There's a learning process and a lot we can help with - we have announced some partnerships with governments and aid agencies already.
16:48 Kevin: "If we do that now, it accrues over the long run as the models get better and we get closer to AGI".
16:48 Question: What are your thoughts on open source / open weights?
16:49 Sam: "I think open source is cool, again if we had more bandwidth we would spend more time on that too." We've got close to that a couple of times, the problem is prioritization. We've been tempted to produce a really good on-device model but that segment is actually pretty well served now.
16:49 Sam: "Very glad it exists, would like to figure out how to contribute"
16:50 Question: Why can't advanced voice mode sing? Can you let us developers play with that?
16:51 Kevin: There are things we can't have it sing - it can't sing copyrighted songs, we don't have a license for that. It's easier in finite time to say no and then build it on, there's nuance to getting it right and penalties to getting these kinds of things wrong. "We really want the models to sing too."
16:51 Sam: We can't offer something where we're going to be in really hot legal water, even to developers. "We have to be able to comply with the law."
16:52 Question: Where do you see context windows going? How do you see the balance between context window growth and RAG?
16:53 Sam: Two issues: when will it get to 10m context windows where you can throw everything in? "Long context has gotten weirdly less usage than I would have expected so far." - and when do we get to effectively unlimited context length where you can throw everything you've seen in your entire life in there. That will need a few research breakthroughs, but maybe that could happen within a decade.
16:53 Sam: "Very long context is going to happen and I think is very interesting."
16:53 Question: What do you see as the vision for the new engagement layer and form factor, especially given voice?
16:55 Kevin: "Developers can play a really big part here" - in the trade-off between generality and specificity. Used ChatGPT advanced voice mode in Seoul recently and had it be a live translator from Korean to English and was able to have a full business conversation. Think about the impact this has on travel and tourism. But ChatGPT is not optimized for that, you have to prompt it right. You want this universal translator in your pocket. "There's a huge opportunity for the creativity of an audince like this to come in and solve problems that we don't have the expertise to"
16:56 Sam talks about a future vision of screens that can dynamically render whatever you need and be a completely different way of using a computer.
16:56 ... and we're at time.
17:02 Thanks for following along with my live blogging experiment. This was fun! I will definitely try this again sometime in the future.
More recent articles
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026
- Profiling Hacker News users based on their comments - 21st March 2026
- Thoughts on OpenAI acquiring Astral and uv/ruff/ty - 19th March 2026