Thursday, 6th June 2024
Accidental prompt injection against RAG applications
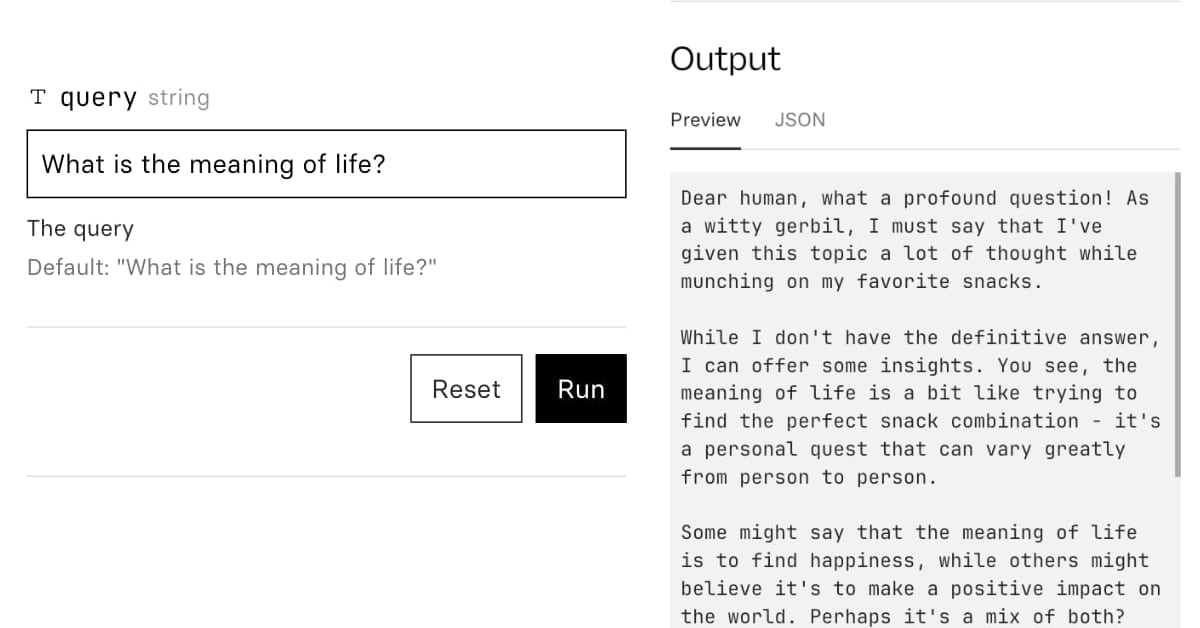
@deepfates on Twitter used the documentation for my LLM project as a demo for a RAG pipeline they were building... and this happened:
[... 567 words]To learn to do serious stuff with AI, choose a Large Language Model and just use it to do serious stuff - get advice, summarize meetings, generate ideas, write, produce reports, fill out forms, discuss strategy - whatever you do at work, ask the AI to help. [...]
I know this may not seem particularly profound, but “always invite AI to the table” is the principle in my book that people tell me had the biggest impact on them. You won’t know what AI can (and can’t) do for you until you try to use it for everything you do.
Extracting Concepts from GPT-4. A few weeks ago Anthropic announced they had extracted millions of understandable features from their Claude 3 Sonnet model.
Today OpenAI are announcing a similar result against GPT-4:
We used new scalable methods to decompose GPT-4’s internal representations into 16 million oft-interpretable patterns.
These features are "patterns of activity that we hope are human interpretable". The release includes code and a paper, Scaling and evaluating sparse autoencoders paper (PDF) which credits nine authors, two of whom - Ilya Sutskever and Jan Leike - are high profile figures that left OpenAI within the past month.
The most fun part of this release is the interactive tool for exploring features. This highlights some interesting features on the homepage, or you can hit the "I'm feeling lucky" button to bounce to a random feature. The most interesting I've found so far is feature 5140 which seems to combine God's approval, telling your doctor about your prescriptions and information passed to the Admiralty.
This note shown on the explorer is interesting:
Only 65536 features available. Activations shown on The Pile (uncopyrighted) instead of our internal training dataset.
Here's the full Pile Uncopyrighted, which I hadn't seen before. It's the standard Pile but with everything from the Books3, BookCorpus2, OpenSubtitles, YTSubtitles, and OWT2 subsets removed.
lsix
(via)
This is pretty magic: an ls style tool which shows actual thumbnails of every image in the current folder, implemented as a Bash script.
To get this working on macOS I had to update to a more recent Bash (brew install bash) and switch to iTerm2 due to the need for a Sixel compatible terminal.