Monday, 29th July 2024
Everlasting jobstoppers: How an AI bot-war destroyed the online job market (via) This story by Joe Tauke highlights several unpleasant trends from the online job directory space at the moment.
The first is "ghost jobs" - job listings that company put out which don't actually correspond to an open role. A survey found that this is done for a few reasons: to keep harvesting resumes for future reference, to imply that the company is successful, and then:
Perhaps the most infuriating replies came in at 39% and 33%, respectively: “The job was filled” (but the post was left online anyway to keep gathering résumés), and “No reason in particular.”
That’s right, all you go-getters out there: When you scream your 87th cover letter into the ghost-job void, there’s a one in three chance that your time was wasted for “no reason in particular.”
Another trend is "job post scraping". Plenty of job listings sites are supported by advertising, so the more content they can gather the better. This has lead to an explosion of web scraping, resulting in vast tracts of listings that were copied from other sites and likely to be out-of-date or no longer correspond to open positions.
Most worrying of all: scams.
With so much automation available, it’s become easier than ever for identity thieves to flood the employment market with their own versions of ghost jobs — not to make a real company seem like it’s growing or to make real employees feel like they’re under constant threat of being replaced, but to get practically all the personal information a victim could ever provide.
I'm not 100% convinced by the "AI bot-war" component of this headline though. The article later notes that the "ghost jobs" report it quotes was written before ChatGPT's launch in November 2022. The story ends with a flurry of examples of new AI-driven tools for both applicants and recruiters, and I've certainly heard anecdotes of LinkedIn spam that clearly has a flavour of ChatGPT to it, but I'm not convinced that the AI component is (yet) as frustration-inducing as the other patterns described above.
Dealing with your AI-obsessed co-worker (TikTok). The latest in Alberta 🤖 Tech's excellent series of skits:
You asked the CEO what he thinks of our project? Oh, you asked ChatGPT to pretend to be our CEO and then asked what he thought of our project. I don't think that counts.
The [Apple Foundation Model] pre-training dataset consists of a diverse and high quality data mixture. This includes data we have licensed from publishers, curated publicly-available or open-sourced datasets, and publicly available information crawled by our web-crawler, Applebot. We respect the right of webpages to opt out of being crawled by Applebot, using standard robots.txt directives.
Given our focus on protecting user privacy, we note that no private Apple user data is included in the data mixture. Additionally, extensive efforts have been made to exclude profanity, unsafe material, and personally identifiable information from publicly available data (see Section 7 for more details). Rigorous decontamination is also performed against many common evaluation benchmarks.
We find that data quality, much more so than quantity, is the key determining factor of downstream model performance.
SAM 2: The next generation of Meta Segment Anything Model for videos and images (via) Segment Anything is Meta AI's model for image segmentation: for any image or frame of video it can identify which shapes on the image represent different "objects" - things like vehicles, people, animals, tools and more.
SAM 2 "outperforms SAM on its 23 dataset zero-shot benchmark suite, while being six times faster". Notably, SAM 2 works with video where the original SAM only worked with still images. It's released under the Apache 2 license.
The best way to understand SAM 2 is to try it out. Meta have a web demo which worked for me in Chrome but not in Firefox. I uploaded a recent video of my brand new cactus tweezers (for removing detritus from my cacti without getting spiked) and selected the succulent and the tweezers as two different objects:
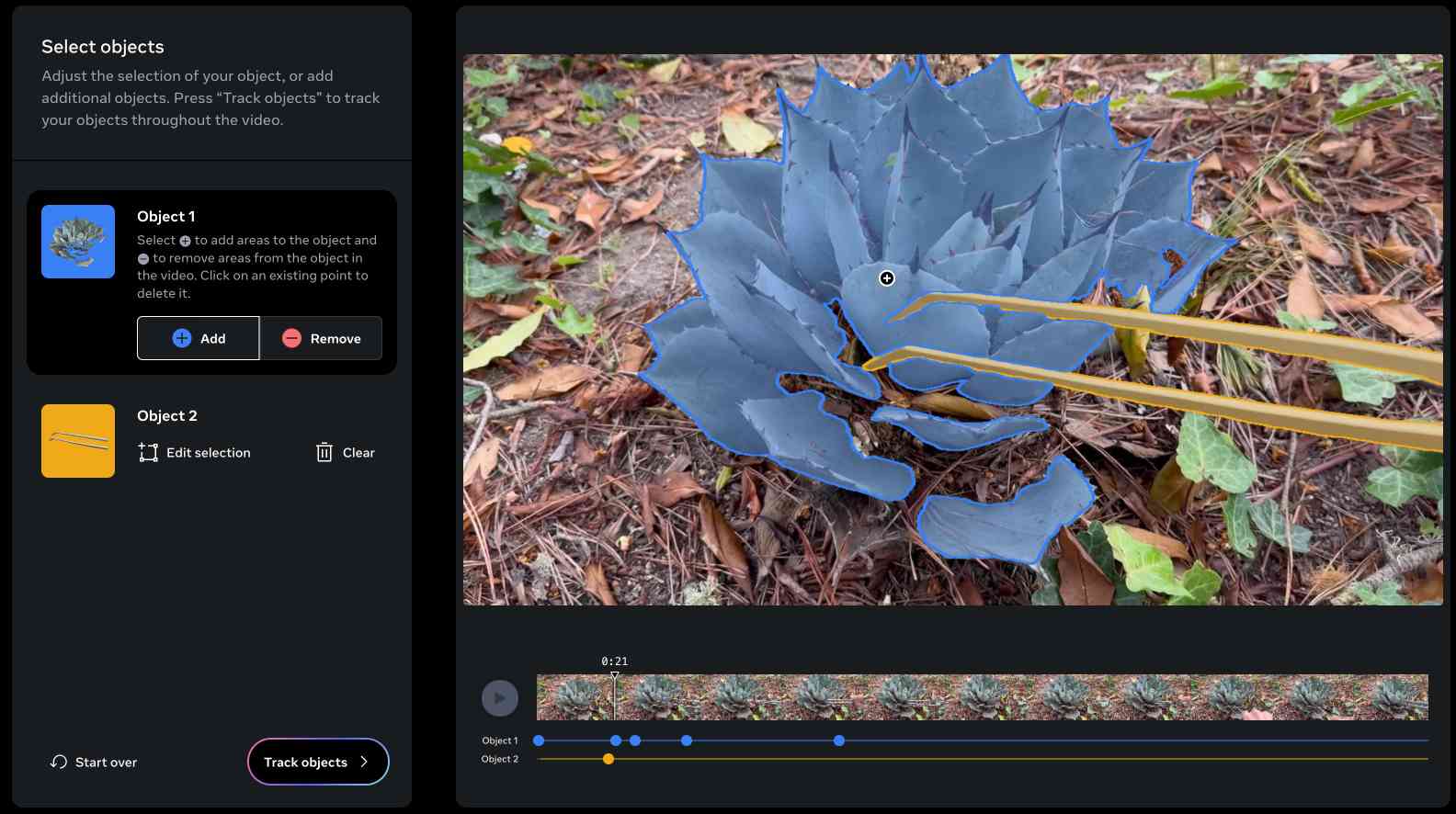
Then I applied a "desaturate" filter to the background and exported this resulting video, with the background converted to black and white while the succulent and tweezers remained in full colour:
Also released today: the full SAM 2 paper, the SA-V dataset of "51K diverse videos and 643K spatio-temporal segmentation masks" and a Dataset explorer tool (again, not supported by Firefox) for poking around in that collection.