Gemini 2.0 Flash “Thinking mode”
19th December 2024
Those new model releases just keep on flowing. Today it’s Google’s snappily named gemini-2.0-flash-thinking-exp, their first entrant into the o1-style inference scaling class of models. I posted about a great essay about the significance of these just this morning.
From the Gemini model documentation:
Gemini 2.0 Flash Thinking Mode is an experimental model that’s trained to generate the “thinking process” the model goes through as part of its response. As a result, Thinking Mode is capable of stronger reasoning capabilities in its responses than the base Gemini 2.0 Flash model.
I just shipped llm-gemini 0.8 with support for the model. You can try it out using LLM like this:
llm install -U llm-gemini
# If you haven't yet set a gemini key:
llm keys set gemini
# Paste key here
llm -m gemini-2.0-flash-thinking-exp-1219 "solve a harder variant of that goat lettuce wolf river puzzle"It’s a very talkative model—2,277 output tokens answering that prompt.
A more interesting example
The best source of example prompts I’ve found so far is the Gemini 2.0 Flash Thinking cookbook—a Jupyter notebook full of demonstrations of what the model can do.
My favorite so far is this one:
What's the area of the overlapping region?
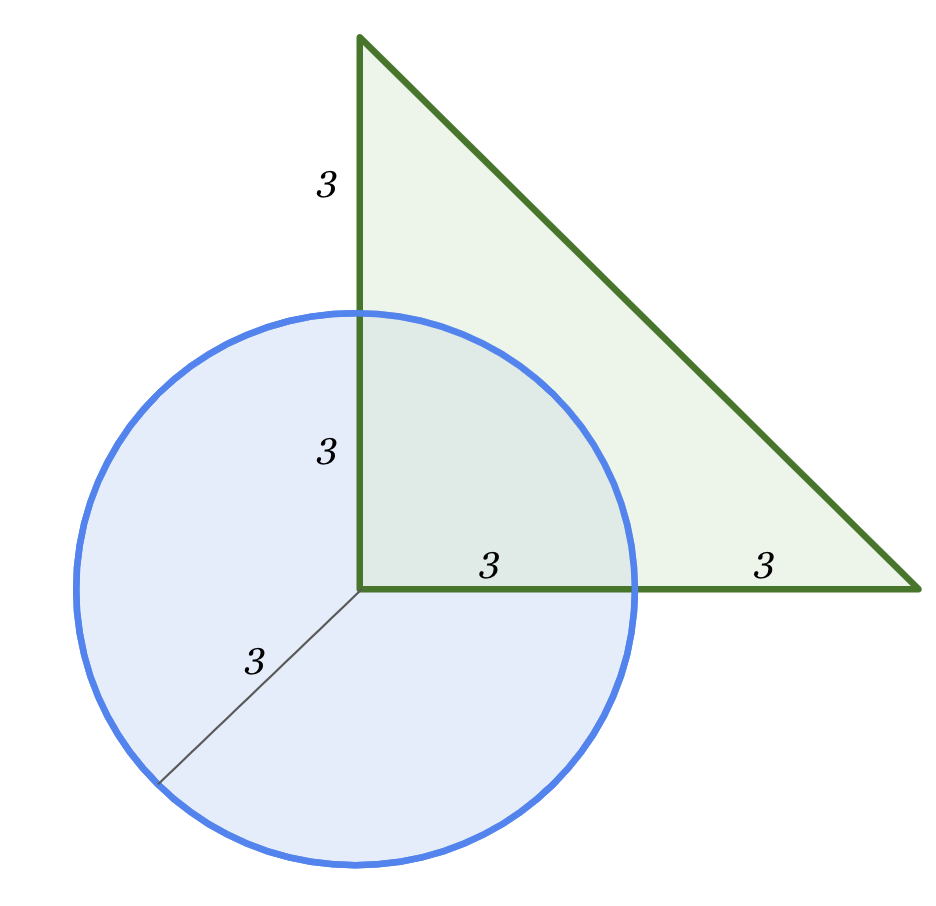
This model is multi-modal!
Here’s how to run that example using llm-gemini:
llm -m gemini-2.0-flash-thinking-exp-1219 \
-a https://storage.googleapis.com/generativeai-downloads/images/geometry.png \
"What's the area of the overlapping region?"Here’s the full response, complete with MathML working. The eventual conclusion:
The final answer is 9π/4
That’s the same answer as Google provided in their example notebook, so I’m presuming it’s correct. Impressive!
How about an SVG of a pelican riding a bicycle?
llm -m gemini-2.0-flash-thinking-exp-1219 \
"Generate an SVG of a pelican riding a bicycle"Here’s the full response. Interestingly it slightly corrupted the start of its answer:
This thought process involves a combination of visual thinking, knowledge of SVG syntax, and iterative refinement. The key is to break down the problem into manageable parts and build up the image piece by piece. Even experienced SVG creators often go through several adjustments before arriving at the final version.00" height="250" viewBox="0 0 300 250" fill="none" xmlns="http://www.w3.org/2000/svg">
<g>
<!-- Bicycle Frame -->
After I manually repaired that to add the <svg opening tag I got this:
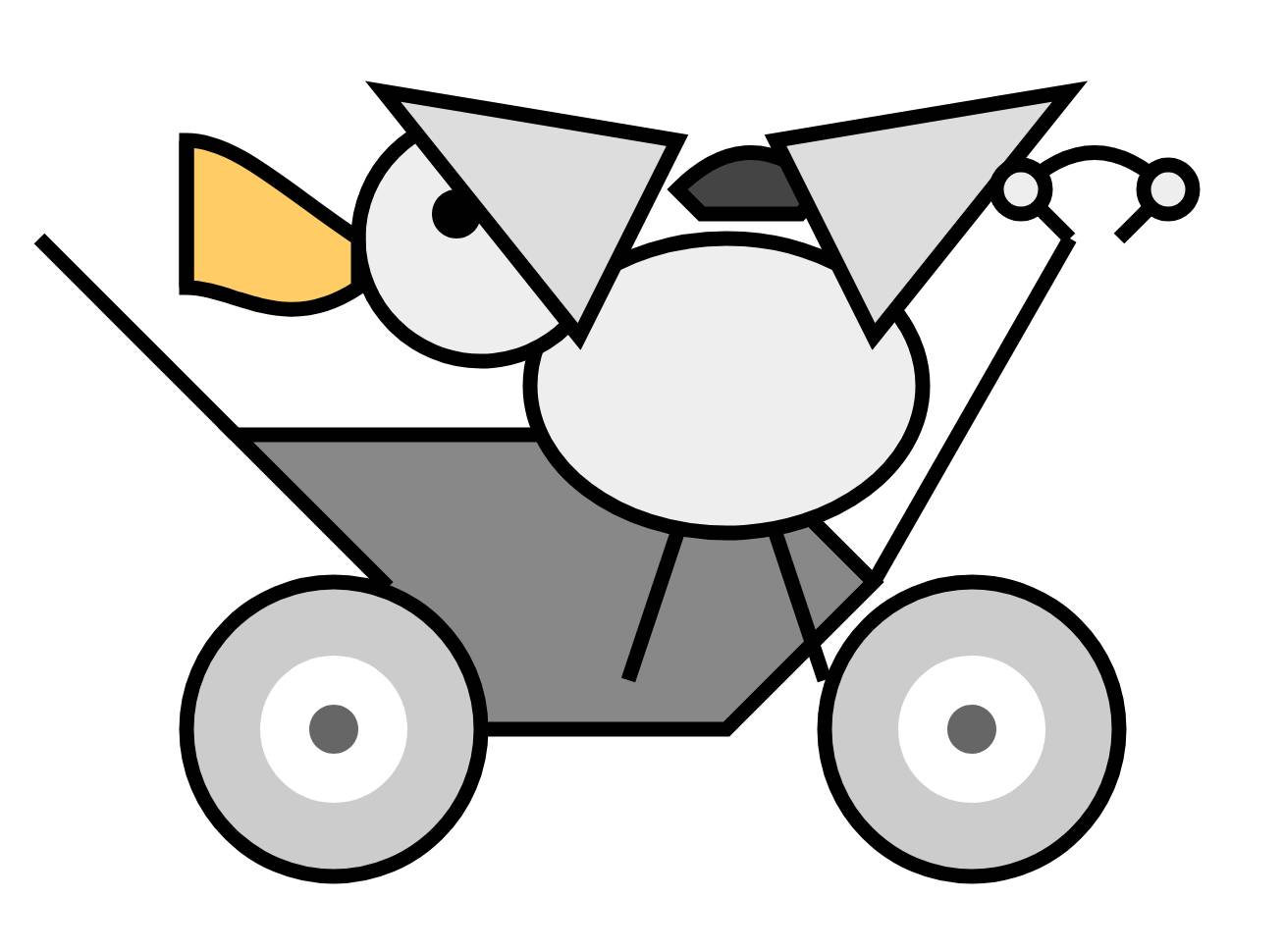
So maybe not an artistic genius, but it’s interesting to read through its chain of thought for that task.
Who’s next?
It’s very clear now that inference scaling is the next big area of research for the large labs. We’ve seen models from OpenAI (o1), Qwen (QwQ), DeepSeek (DeepSeek-R1-Lite-Preview) and now Google Gemini. I’m interested to hear if Anthropic or Meta or Mistral or Amazon have anything cooking in this category.
More recent articles
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026
- Vibe coding SwiftUI apps is a lot of fun - 27th March 2026
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026