Weeknotes: datasette-seaborn, fivethirtyeight-polls
18th September 2020
This week I released Datasette 0.49 and tinkered with datasette-seaborn, dogsheep-beta and polling data from FiveThirtyEight.
datasette-seaborn
Datasette currently has two key plugins for data visualization: datasette-vega for line, bar and scatter charts (powered by Vega-Lite) and datsette-cluster-map for creating clustered marker maps.
I’m always looking for other interesting visualization opportunities. Seaborn 0.11 came out last week and is a very exciting piece of software.
Seaborn focuses on statistical visualization tools—histograms, boxplots and the like—and represents 8 years of development lead by Michael Waskom. It’s built on top of Matplotlib and exhibits meticulously good taste.
So I’ve started building datasette-seaborn, a plugin which provides an HTTP interface for generating Seaborn charts using data stored in Datasette.
It’s still very alpha but early results are promising. I’ve chosen to implement it as a custom output renderer—so adding .seaborn to any Datasette table (plus some querystring parameters) will output a rendered PNG chart of that data, just like how .json or csv give you that data in different export formats.
Here’s an example chart generated by the plugin using the fabulous palmerpenguins dataset (intended as a new alternative to Iris).
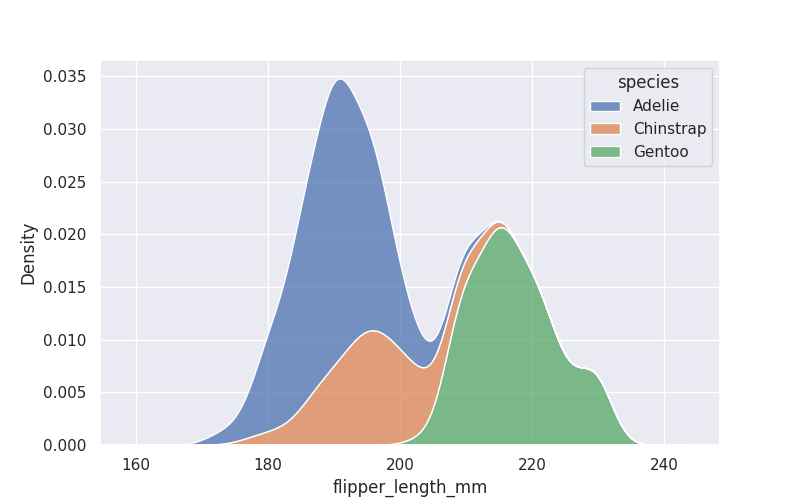
I generated this image from the following URL:
https://datasette-seaborn-demo.datasette.io/penguins/penguins.seaborn?_size=1000&_seaborn=kdeplot&_seaborn_x=flipper_length_mm&_seaborn_hue=species&_seaborn_multiple=stack
This interface should be considered unstable and likely to change, but it illustrates the key idea behind the plugin: use ?_seaborn_x parameters to feed in options for the chart that you want to render.
The two biggest issues with the plugin right now are that it renders images on the main thread, potentially blocking the event loop, and it passes querystring arguments directly to seaborn without first validating them which is almost certainly a security problem.
So very much an alpha, but it’s a promising start!
dogsheep-beta
Dogsheep Beta provides faceted search across my personal data from a whole variety of different sources.
I demo’d it at PyCon AU a few weeks ago, and promised that a full write-up would follow. I still need to honour that promise! I’m figuring out how to provide a good interactive demo at the moment that doesn’t expose my personal data.
I added sort by date in addition to sort by relevance in version 0.7 this week.
fivethirtyeight-polls
FiveThirtEight have long published the data behind their stories in their fivethirtyeight/data GitHub repository, and I’ve been using that data to power a Datasette demo ever since I first released the project.
They run an index of their data projects at data.fivethirtyeight.com, and this week I noticed that they list US election polling data there that wasn’t being picked up by my fivethirtyeight.datasettes.com site.
It turns out this is listed in the GitHub repository as a README.md file but without the actual CSV data. Instead, the README links to external CSV files with URLs like https://projects.fivethirtyeight.com/polls-page/president_primary_polls.csv
It looks to me like they’re running their own custom web application which provides the CSV data as an export format, rather than keeping that CSV data directly in their GitHub repository.
This makes sense—I imagine they run a lot of custom code to help them manage their data—but does mean that my Datasette publishing scripts weren’t catching their polling data.
Since they release their data as Creative Commons Attribution 4.0 International I decided to start archiving it on GitHub, where it would be easier to automate.
I set up simonw/fivethirtyeight-polls to do just that. It’s a classic implementation of the git-scraping pattern: it runs a workflow script four times a day which fetches their latest CSV files and commits them to a repo. This means I now have a commit history of changes they have made to their polling data!
I updated my FiveThirtyEight Datasette script to publish that data as a new polls.db database, which is now being served at fivethirtyeight.datasettes.com/polls.
And since that Datasette instance runs the datasette-graphql plugin, you can now use GraphQL to explore FiveThirtyEight’s most recent polling data at https://fivethirtyeight.datasettes.com/graphql/polls—here’s an example query.
github-to-sqlite get
github-to-sqlite lets you fetch data from the GitHub API and write it into a SQLite database.
This week I added a sub-command for hitting the API directly and getting back data on the console, inspired by the fetch subcommand in twitter-to-sqlite. This is useful for trying out new APIs, since it both takes into account your GitHub authentication credentials (from an environment variable or an auth.json file) and can handle Link header pagination.
This example fetches all of my repos, paginating across multiple API requests:
github-to-sqlite get /users/simonw/repos --paginate
You can use the --nl option to get back the results as newline-delimited JSON. This makes it easy to pipe them directly into sqlite-utils like this:
github-to-sqlite get /users/simonw/repos --paginate --nl \
| sqlite-utils insert simonw.db repos - --nl
See Inserting JSON data in the sqlite-utils documentation for an explanation of what this is doing.
TIL this week
- Open a debugging shell in GitHub Actions with tmate
- Talking to a PostgreSQL service container from inside a Docker container
Releases this week
- dogsheep-beta 0.7.1—2020-09-17
- dogsheep-beta 0.7—2020-09-17
- github-to-sqlite 2.6—2020-09-17
- datasette 0.49.1—2020-09-15
- datasette-ics 0.5—2020-09-14
- datasette-copyable 0.3—2020-09-14
- datasette-atom 0.8—2020-09-14
- datasette-yaml 0.1—2020-09-14
- datasette 0.49—2020-09-14
- datasette 0.49a1—2020-09-14
- datasette-seaborn 0.1a1—2020-09-11
- datasette-seaborn 0.1a0—2020-09-11
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026