How much can you learn from just two columns?
15th June 2020
Derek Willis shared an intriguing dataset this morning: a table showing every Twitter account followed by an official GOP congressional Twitter account.
He published it here using Datasette. It’s a single table containing 385,979 rows—each row is a username, account_name pair, where username is the Twitter account that is being followed and account_name is the congressional Twitter account that’s following it.
Here’s some sample data:
| username | account_name |
|---|---|
| njhotline | SenatorTimScott |
| emilykpierce | RobWittman |
| jessblevinsoh | OHPressSec |
| familylink | SenMikeLee |
| howardsnowdon | RepThomasMassie |
| pattidomm | SenCapito |
How much can we learn from just these two columns?
Which accounts have the most GOP congressional followers?
Let’s start with a simple aggregation: which accounts on Twitter have the most GOP congressional followers?
select
username,
count(*) as num_gop_followers
from
following
group by
username
order by
num_gop_followers descAll we’re doing here is counting the number of times a unique username (an account that is being followed) shows up in our table, then sorting by those counts.
Here are the result. The top ten are:
| username | num_gop_followers |
|---|---|
| housegop | 231 |
| gopleader | 229 |
| realdonaldtrump | 219 |
| vp | 216 |
| speakerryan | 207 |
| whitehouse | 207 |
| stevescalise | 198 |
| chadpergram | 195 |
| potus | 195 |
| foxnews | 187 |
Adding a “view more” link
Wouldn’t it be useful if you could see which accounts those 231 followers of @housegop were?
We can do that in Datasette without a SQL query—we can instead use the form on the table page to construct a filter—or construct a querystring URL directly. Here are the 5 GOP congressional accounts following @cityofdallas:
https://official-gop-following.herokuapp.com/following/following?username=cityofdallas
Let’s add that link to our original top-followed query. Datasette automatically links any value that begins with https://, so we can use SQL concatenation trick (with the || concatenation operator) to construct that URL as part of the query:
select
username,
count(*) as num_gop_followers,
'https://official-gop-following.herokuapp.com/following/following?username=' || username as list_of_gop_followers
from
following
group by
username
order by
num_gop_followers descHere’s that query. The first five rows look like this:
| username | num_gop_followers | list_of_gop_followers |
|---|---|---|
| housegop | 231 | https://official-gop-following.herokuapp.com/following/following?username=housegop |
| gopleader | 229 | https://official-gop-following.herokuapp.com/following/following?username=gopleader |
| realdonaldtrump | 219 | https://official-gop-following.herokuapp.com/following/following?username=realdonaldtrump |
| vp | 216 | https://official-gop-following.herokuapp.com/following/following?username=vp |
| speakerryan | 207 | https://official-gop-following.herokuapp.com/following/following?username=speakerryan |
Congressional accounts who aren’t following certain accounts
Since there are only 279 congressional GOP Twitter accounts, how about seeing who are the 279—219 = 60 accounts that aren’t following @realdonaldtrump?
Let’s construct a SQL query for this, using a sub-select:
select
distinct account_name
from
following
where
account_name not in (
select
account_name
from
following
where
username = 'realdonaldtrump'
)A neat thing we can do here is to parametrize that query. We can swap the hard-coded 'realdonaldtrump' value for a named parameter, :name, instead:
select
distinct account_name
from
following
where
account_name not in (
select
account_name
from
following
where
username = :name
)Now when we visit that in Datasette it looks like this:
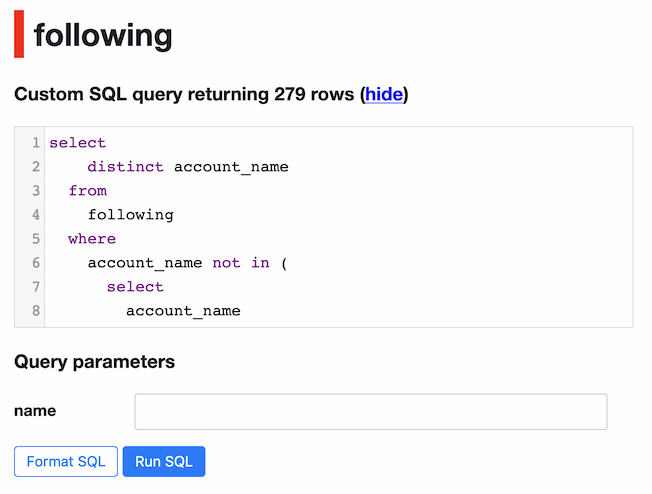
We can add ?name=realdonaldtrump to the URL (or submit the form and save the resulting URL) to link to results for one individual.
We’ve essentially created a new mini-application here—complete with an input form—just by bookmarking a URL in Datasette.
Let’s make the query a bit more interesting by including a count of the number of accounts those congress-people ARE following, and sorting by that.
select
account_name,
count(*) as num_accounts_they_follow
from
following
where
account_name not in (
select
account_name
from
following
where
username = 'realdonaldtrump'
)
group by
account_name
order by
num_accounts_they_follow descHere are the results.
| account_name | num_accounts_they_follow |
|---|---|
| ChuckGrassley | 13475 |
| VernBuchanan | 8560 |
| CynthiaLummis | 5793 |
| GovAbbott | 4423 |
| SenatorTimScott | 3846 |
@ChuckGrassley follows 13,475 accounts but none of them are the president!
Most similar accounts, based on number of shared follows
One last query. This time we’re going to look at which accounts are “most similar” to each other, based on the largest overlap of follows. Here’s the SQL for that:
select
:name as representative,
account_name as similar_representative,
count(*) as num_shared_follows
from
following
where
username in (
select
username
from
following
where
account_name = :name
)
and account_name != :name
group by
account_name
order by
num_shared_follows descAgain, we’re using a :name placeholder. Here are the congressional accounts that are most similar to @MikeKellyPA.
What else can you do?
I’m pretty impressed at how much insight can be gained using SQL against just a two column table.
This post started as a Twitter thread. Charles Arthur suggested cross-referencing this against other sources such as the GovTrack ideology analysis of congressional candidates. This is a great idea! It’s also very feasible, given that much of the data underlying GovTrack is available on GitHub. Import that into Datasette alongside Derek’s follower data and you could construct some very interesting SQL joins indeed.
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026