Datasette Facets
20th May 2018
Datasette 0.22 is out with the most significant new feature I’ve added since the initial release: faceted browse.
Datasette lets you deploy an instant web UI and JSON API for any SQLite database. csvs-to-sqlite makes it easy to create a SQLite database out of any collection of CSV files. Datasette Publish is a web app that can run these combined tools against CSV files you upload from your browser. And now the new Datasette Facets feature lets you explore any CSV file using faceted navigation with a couple of clicks.
Exploring characters from Marvel comics
Let’s use facets to explore every character in the Marvel Universe.
FiveThirtyEight have published a CSV file of 16,376 characters from Marvel comics, scraped from Wikia as part of the research for their 2014 story Comic Books Are Still Made By Men, For Men And About Men.
Here’s that CSV file loaded into the latest version of Datasette:
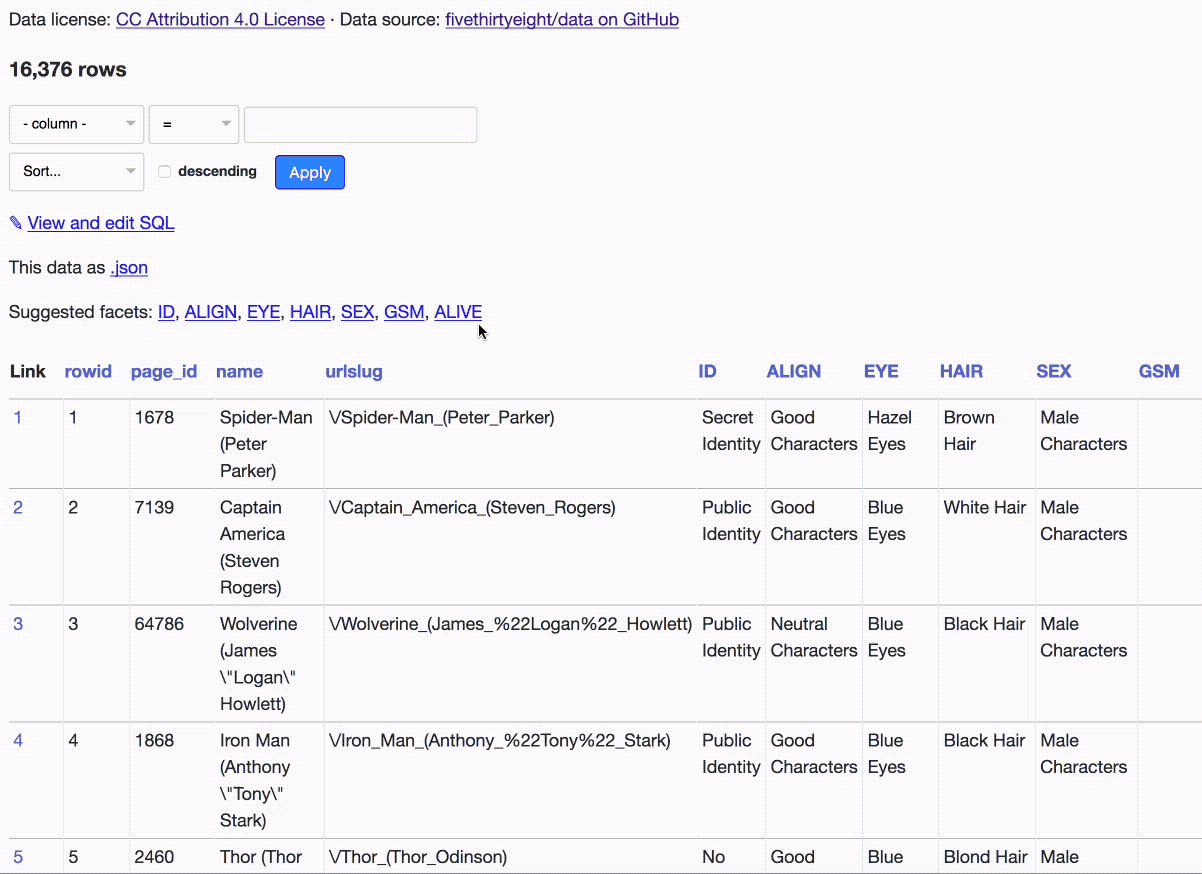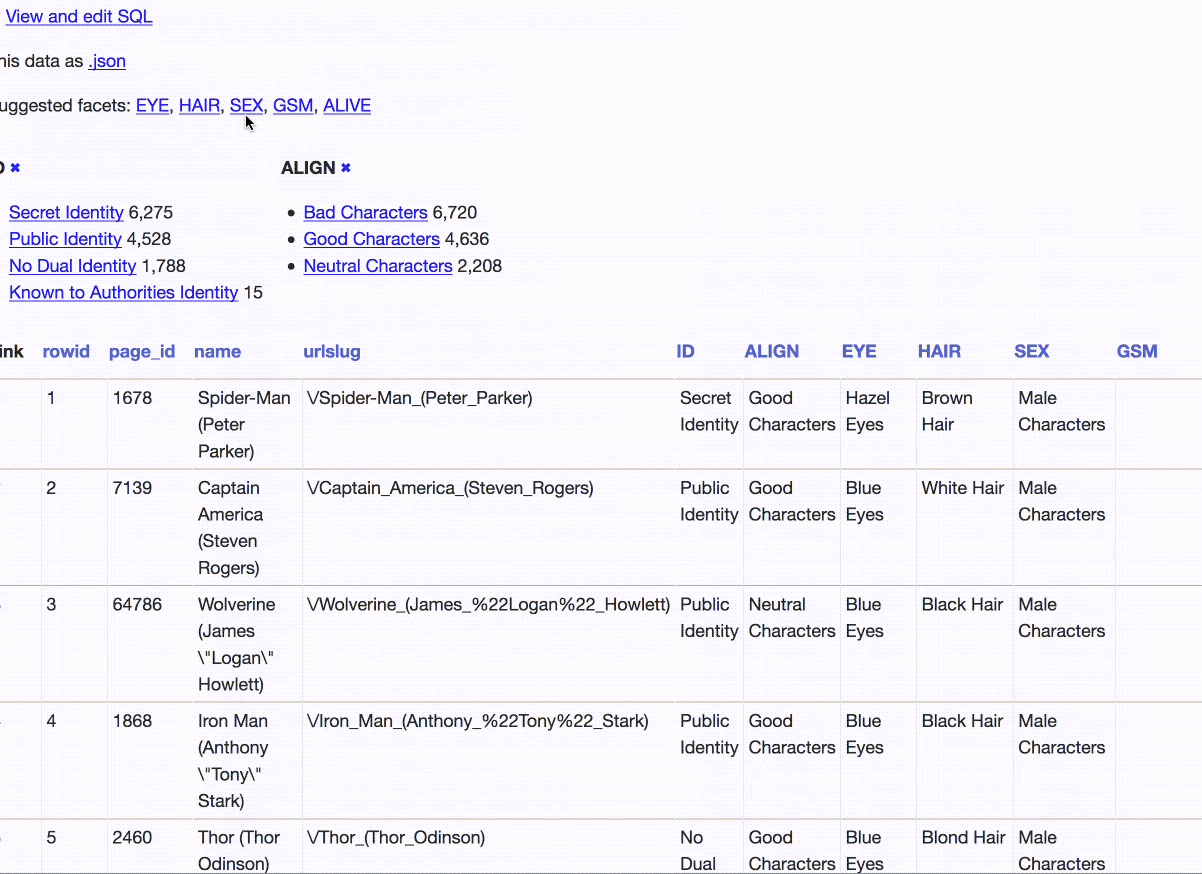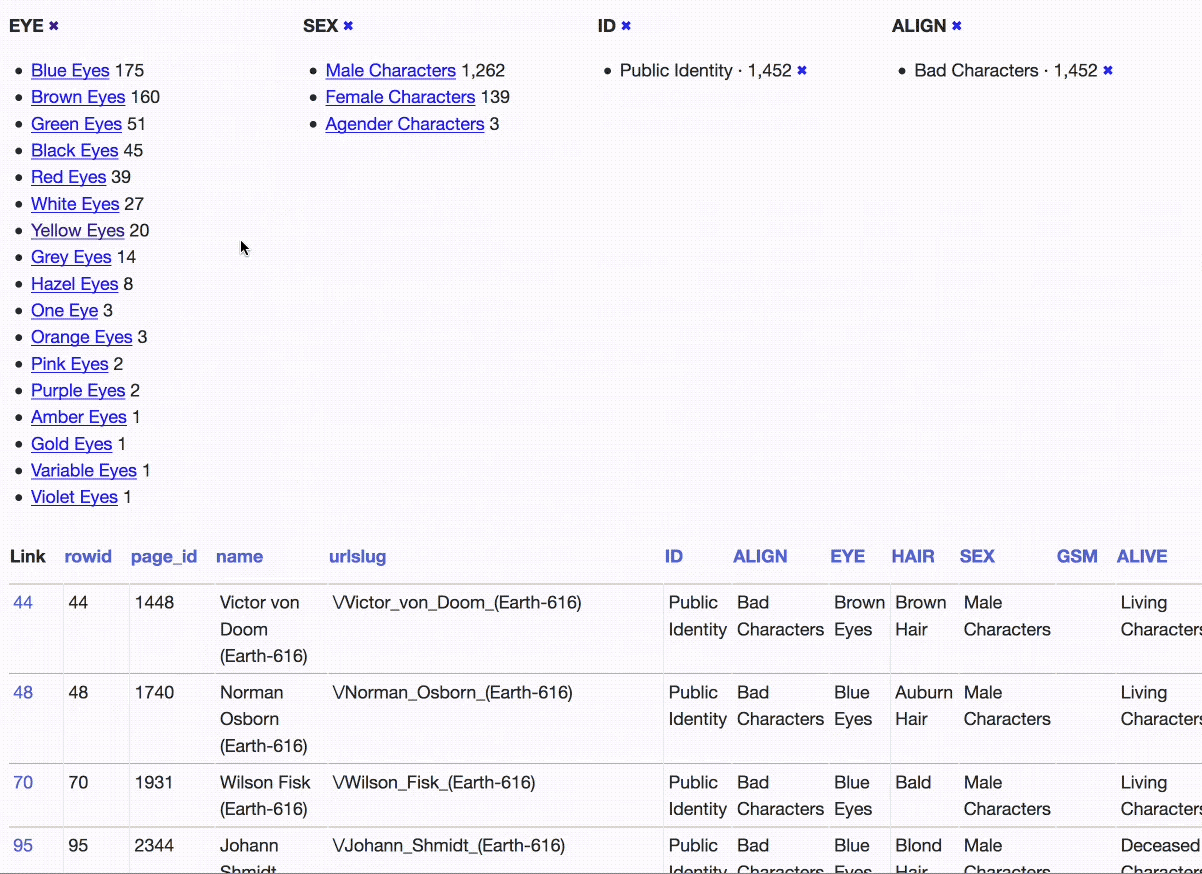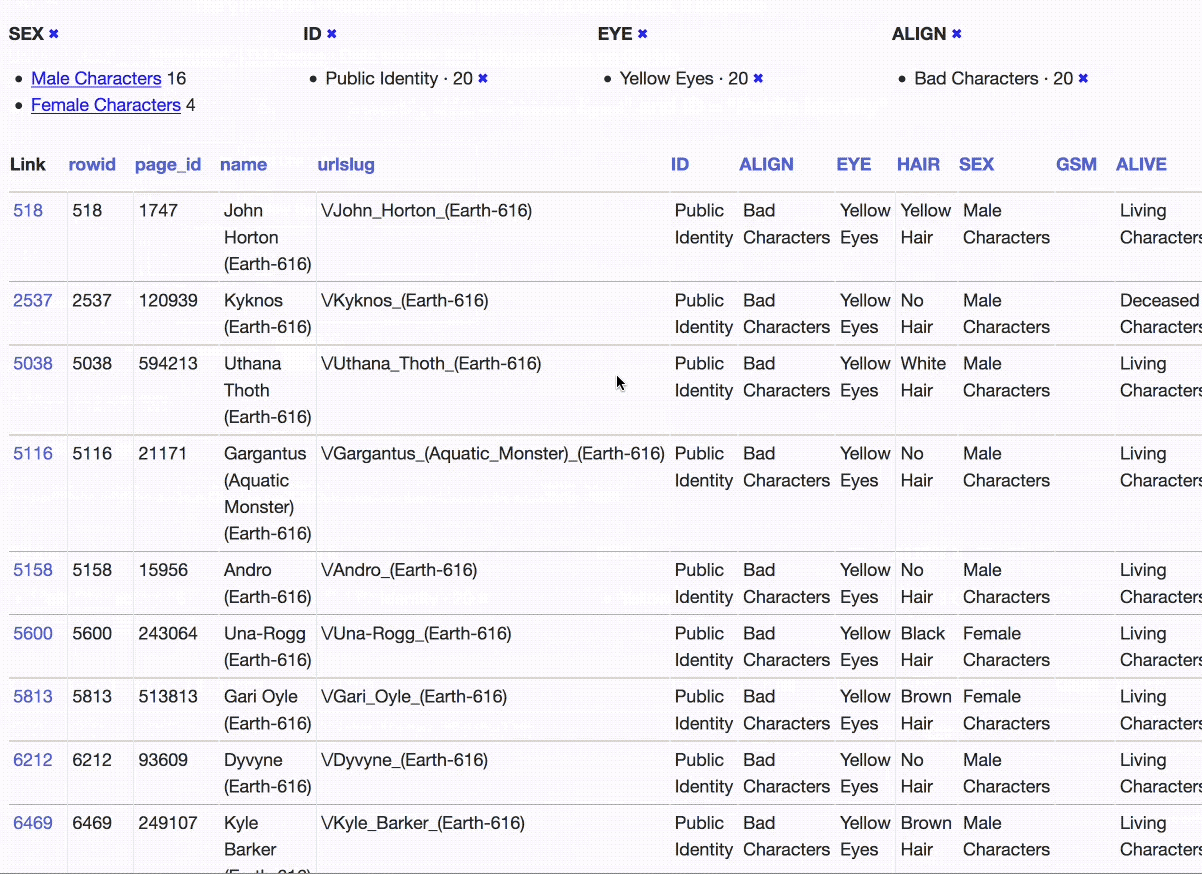
We start by applying the identity status, alignment and gender facets. Then we filter down to just the bad characters with a public identity, and apply the eye colour facet. Now we can filter to just the 20 bad characters with a public identity and yellow eyes.
At each stage along the way we could see numerical summaries of the other facets. That’s a pretty sophisticated piece of analysis we’ve been able to run with just a few clicks (and it works responsively on mobile as well).
I’ve published a full copy of everything else in the FiveThirtyEight data repository, which means you can find plenty more examples of facets in action at https://fivethirtyeight.datasettes.com/—one example: Actions under the Antiquities Act, faceted by states, pres_or_congress, action and current_agency.
Analyzing GSA IT Standards with Datasette Publish
The US government’s General Services Administration have a GitHub account, and they use it to publish a repository of assorted data as CSVs.
Let’s take one of those CSVS and analyze it with Datasette Facets, using the Datasette Publish web app to upload and process the CSV.
We’ll start with the it-standards.csv file, downloaded from their repo. We’ll upload it to Datasette Publish and add some associated metadata:
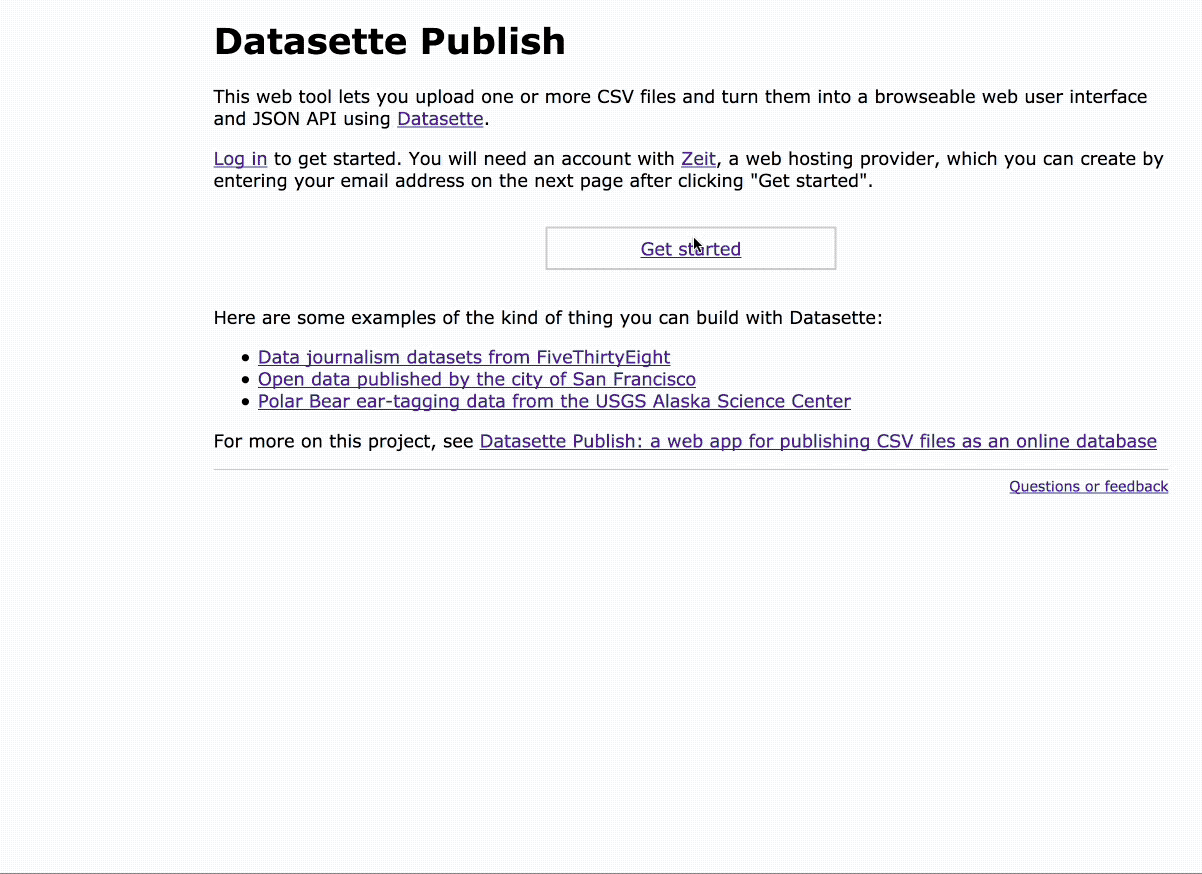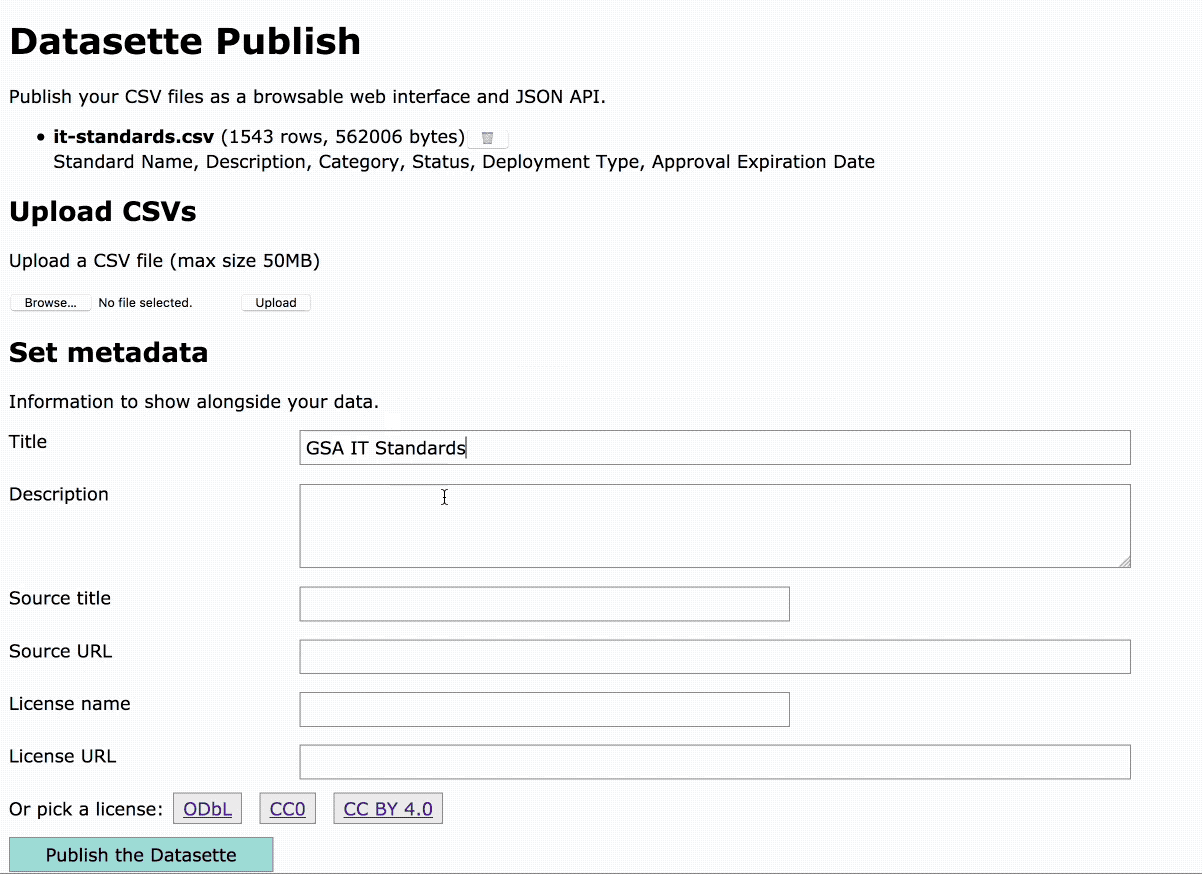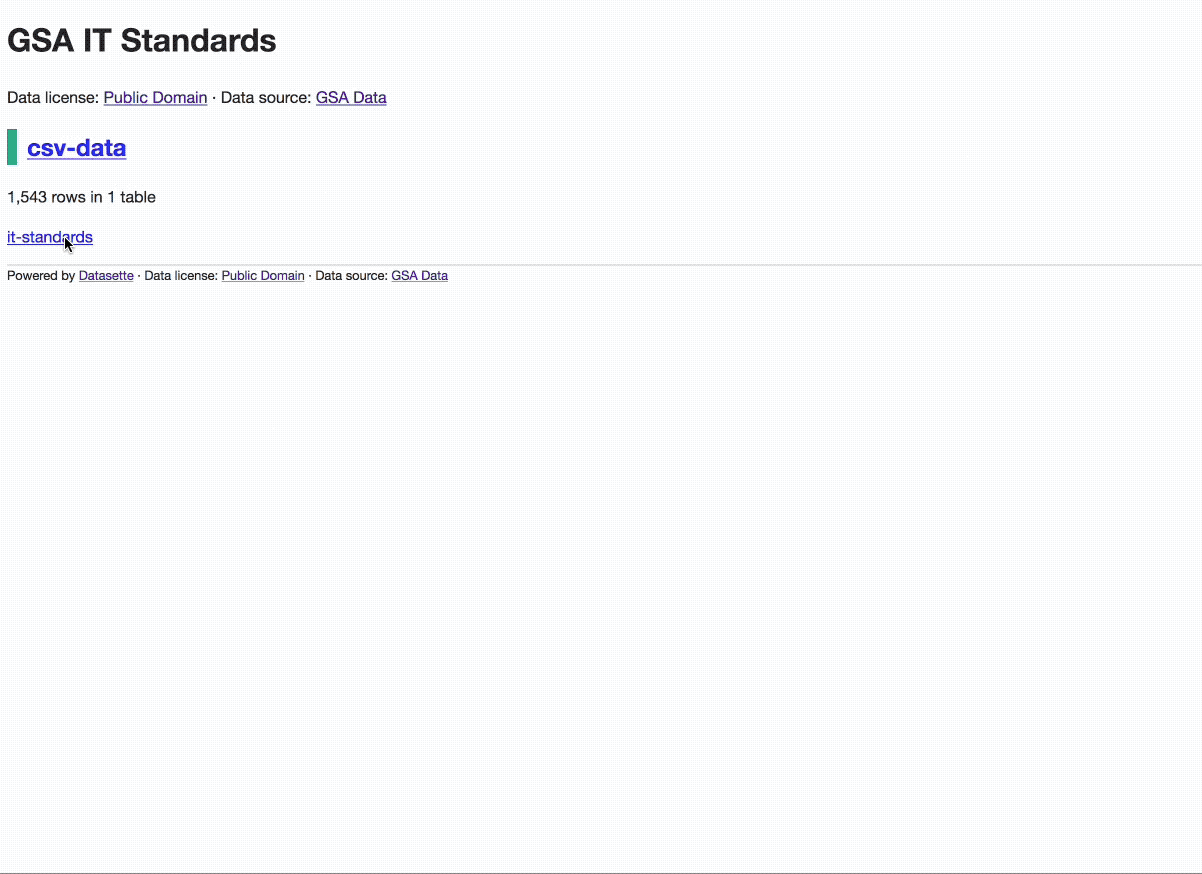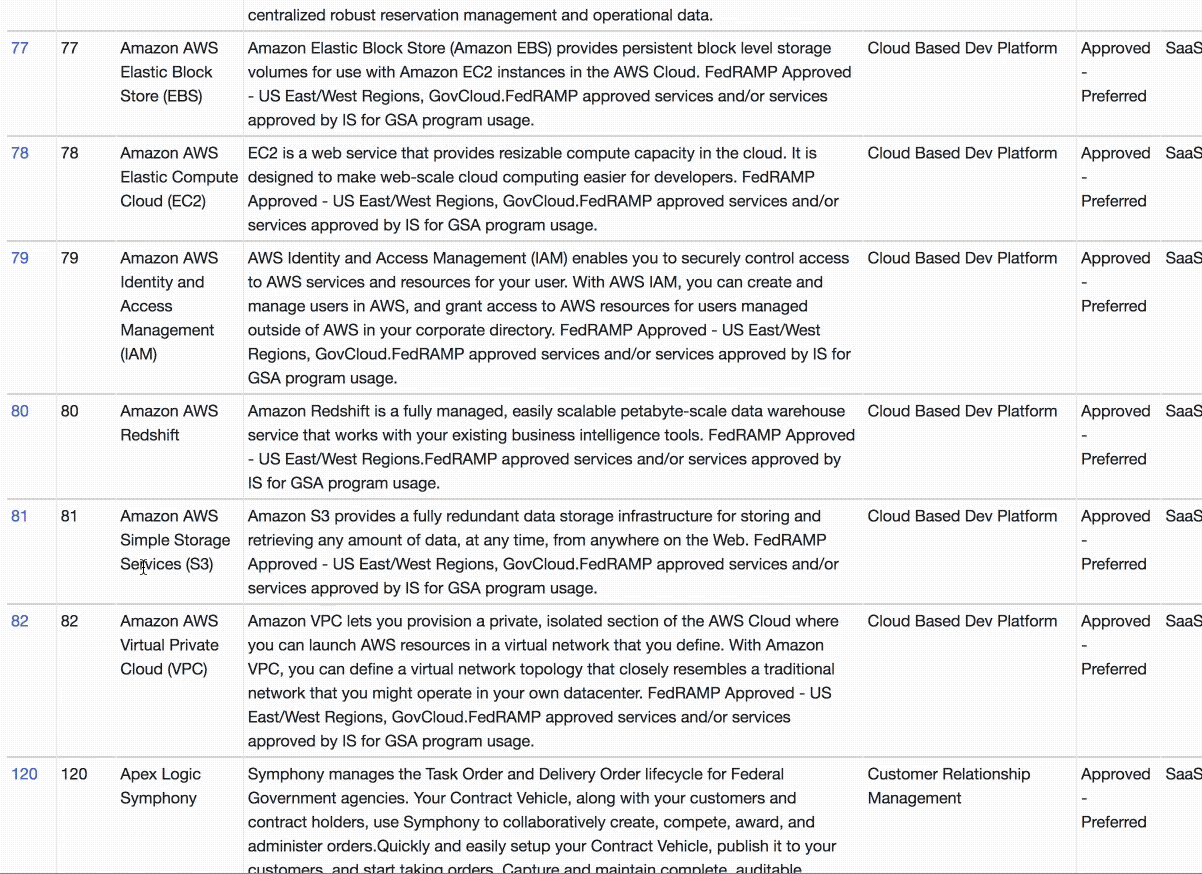
Here’s the result, with the Status and Deployment Type facets applied. And here’s a query showing just SaaS tools with status Approved—Preferred.
European Power Stations
The Open Power System Data project publishes data about electricity systems. They publish data in a number of formats, including SQLite databases. Let’s take their conventional_power_plants.sqlite file and explore it with Datasette. With Datasette installed, run the following commands in your terminal:
wget https://data.open-power-system-data.org/conventional_power_plants/2018-02-27/conventional_power_plants.sqlite
datasette conventional_power_plants.sqlite
This will start Datasette running at http://127.0.0.1:8001/ ready for you to explore the data.
Next we can publish the SQLite database directly to the internet using the datasette publish command-line tool:
$ datasette publish now conventional_power_plants.sqlite \
--source="Open Power System Data. 2018. Data Package Conventional power plants. Version 2018-02-27" \
--source_url="https://data.open-power-system-data.org/conventional_power_plants/2018-02-27/" \
--title="Conventional power plants" \
--branch=master
> Deploying /private/var/folders/jj/fngnv0810tn2lt_kd3911pdc0000gp/T/tmpufvxrzgp/datasette under simonw
> https://datasette-tgngfjddix.now.sh [in clipboard] (sfo1) [11s]
> Synced 3 files (1.28MB) [11s]
> Building…
> ▲ docker build
Sending build context to Docker daemon 1.343 MBkB
> Step 1/7 : FROM python:3
> 3: Pulling from library/python
> 3d77ce4481b1: Already exists
> 534514c83d69: Already exists
...
> Successfully built da7ac223e8aa
> Successfully tagged registry.now.systems/now/3d6d318f0da06d3ea1bc97417c7dc484aaac9026:latest
> ▲ Storing image
> Build completed
> Verifying instantiation in sfo1
> [0] Serve! files=('conventional_power_plants.sqlite',) on port 8001
> [0] [2018-05-20 22:51:51 +0000] [1] [INFO] Goin' Fast @ http://0.0.0.0:8001
> [0] [2018-05-20 22:51:51 +0000] [1] [INFO] Starting worker [1]
Finally, let’s give it a nicer URL using now alias:
now alias https://datasette-tgngfjddix.now.sh conventional-power-plants.now.sh
The result can now be seen at https://conventional-power-plants.now.sh/
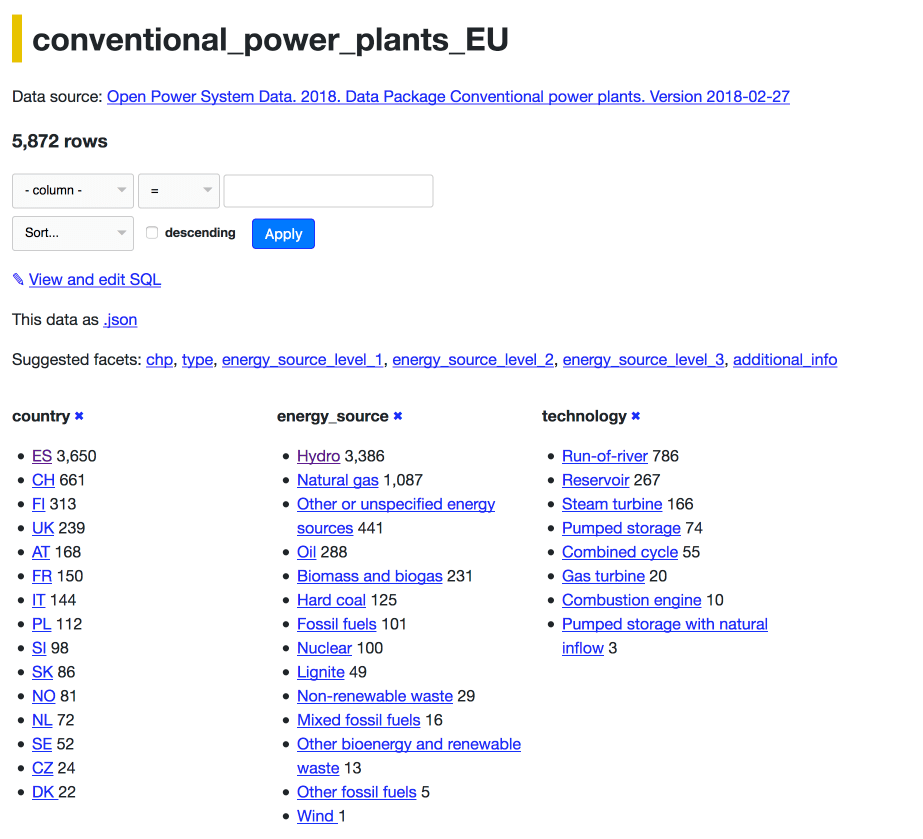
Here’s every conventional power plant in Europe faceted by country, energy source and technology.
Implementation notes
I love faceted search engines. One of my first approaches to understanding any new large dataset has long been to throw it into a faceted search engine and see what comes out. In the past I’ve built them using Solr, Elasticsearch, PostgreSQL and even Whoosh. I guess it was inevitable that I’d try to build one with SQLite.
You can follow the development of Datasette Facets in the now-closed issue #255 on GitHub.
Facets are requested by appending one or more ?_facet=colname parameters to the URL. This causes Datasette to run the following SQL query for each of those specified columns:
select colname as value, count(*) as count
from tablename where (current where clauses)
group by colname order by count desc limit 31
For large tables, this could get expensive. Datasette supports time limits for SQLite queries, and facets are given up to 200ms (by default, this limit can be customized) to finish executing. If the query doesn’t complete in the given time the user sees a warning that the facet could not be displayed.
We ask for 31 values in the limit clause even though we only display 30. This lets us detect if there are more values available and show a ... indicator to let the user know that the facets were truncated.
Datasette also suggests facets that you might want to apply. This is implemented using another query, this time run against every column that is not yet being used as a facet. If a table has 20 columns this means 20 queries, so they run with an even tighter 50ms time limit. The query looks like this:
select distinct colname
from tablename where (current where clauses)
limit 31
All we are doing here is trying to determine if the column in question has less than 30 unique values. The limit clause here means that if you run this query against a column with entirely distinct values (the primary key for example) the query will terminate extremely quickly—after it has found just the first 31 values.
Once the query has executed, we count the distinct values and check to see if this column, when used as a facet:
- Will return 30 or less unique options
- Will return more than one unique option
- Will return less unique options than the current total number of filtered rows
If the query takes longer than 50ms we terminate it and do not suggest that column as a potential facet.
Facets via JSON
As with everything in Datasette, the facets you can view in your browser are also available as part of the JSON API (which ships with CORS headers so you can easily fetch data from JavaScript running in a browser on any web page).
To get back JSON, add .json to the path (before the first ?). Here’s that power plants example returned as JSON: https://conventional-power-plants.now.sh/conventional_power_plants-e3c301c/conventional_power_plants_EU.json?_facet=country&_facet=energy_source&_facet=technology
Please let me know if you build something interesting with Datasette Facets!
More recent articles
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026
- The new GPT-5.6 family: Luna, Terra, Sol - 9th July 2026
- sqlite-utils 4.0, now with database schema migrations - 7th July 2026