27th March 2025 - Link Blog
Tracing the thoughts of a large language model. In a follow-up to the research that brought us the delightful Golden Gate Claude last year, Anthropic have published two new papers about LLM interpretability:
- Circuit Tracing: Revealing Computational Graphs in Language Models extends last year's interpretable features into attribution graphs, which can "trace the chain of intermediate steps that a model uses to transform a specific input prompt into an output response".
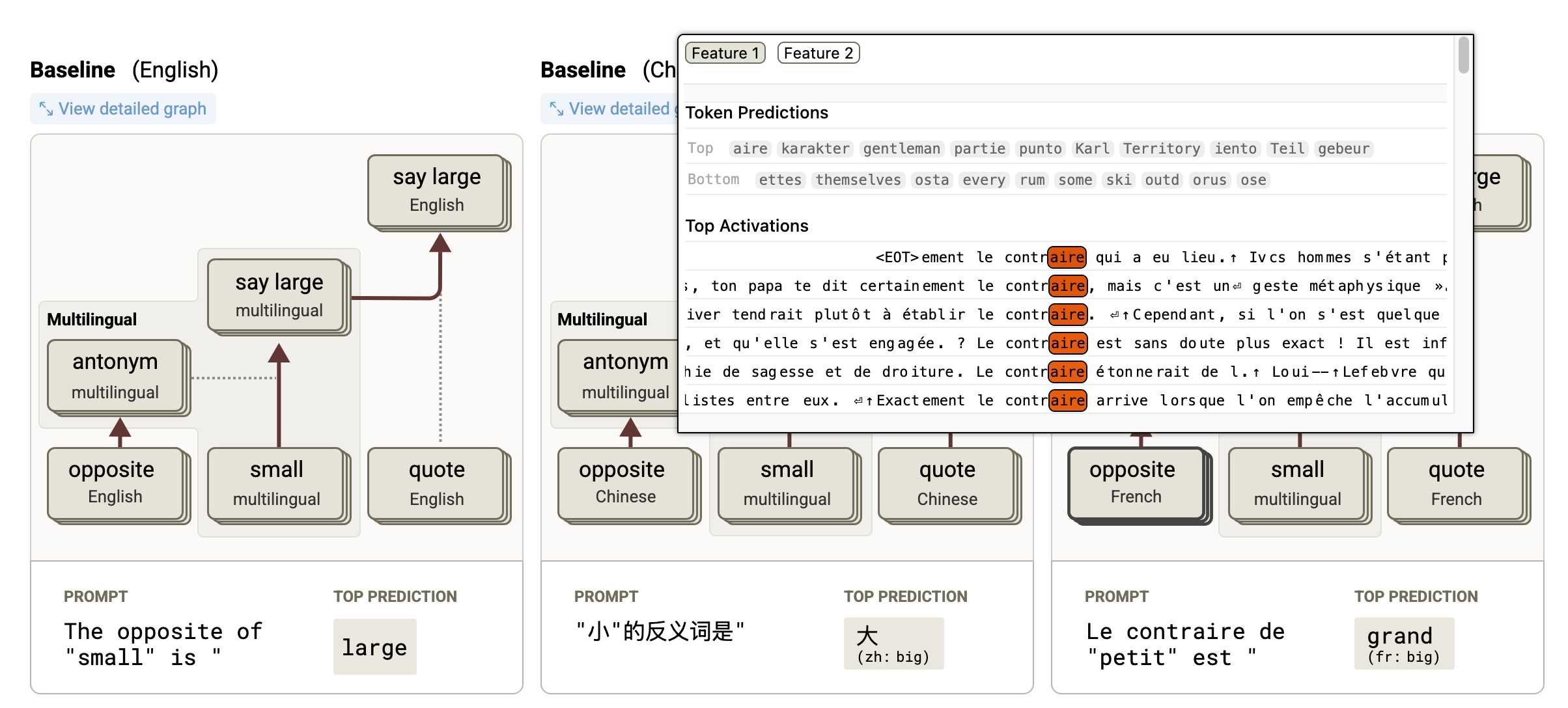
- On the Biology of a Large Language Model uses that methodology to investigate Claude 3.5 Haiku in a bunch of different ways. Multilingual Circuits for example shows that the same prompt in three different languages uses similar circuits for each one, hinting at an intriguing level of generalization.
To my own personal delight, neither of these papers are published as PDFs. They're both presented as glorious mobile friendly HTML pages with linkable sections and even some inline interactive diagrams. More of this please!
Recent articles
- Meta's new model is Muse Spark, and meta.ai chat has some interesting tools - 8th April 2026
- Anthropic's Project Glasswing - restricting Claude Mythos to security researchers - sounds necessary to me - 7th April 2026
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026