18th February 2025 - Link Blog
Andrej Karpathy's initial impressions of Grok 3. Andrej has the most detailed analysis I've seen so far of xAI's Grok 3 release from last night. He runs through a bunch of interesting test prompts, and concludes:
As far as a quick vibe check over ~2 hours this morning, Grok 3 + Thinking feels somewhere around the state of the art territory of OpenAI's strongest models (o1-pro, $200/month), and slightly better than DeepSeek-R1 and Gemini 2.0 Flash Thinking. Which is quite incredible considering that the team started from scratch ~1 year ago, this timescale to state of the art territory is unprecedented.
I was delighted to see him include my Generate an SVG of a pelican riding a bicycle benchmark in his tests:
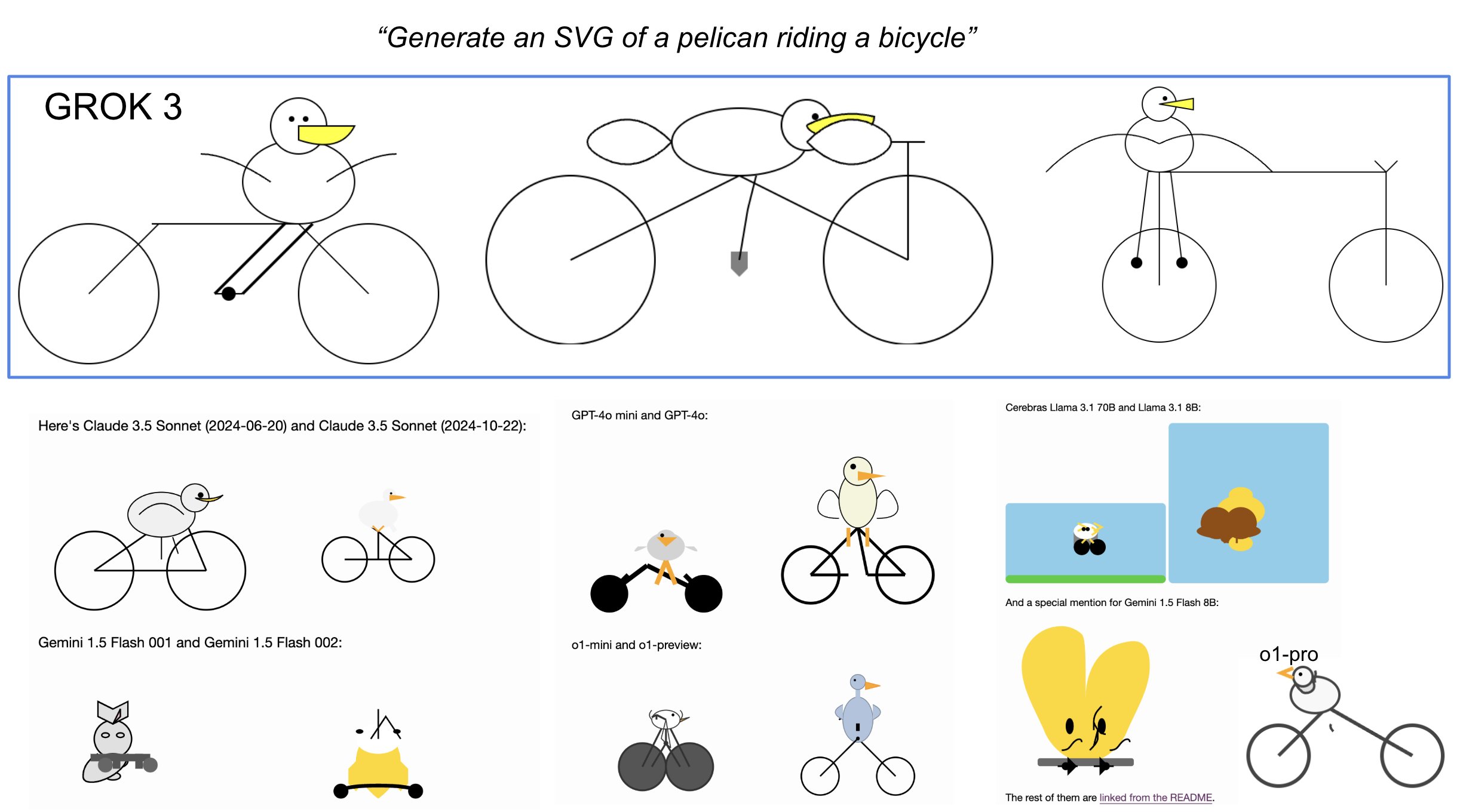
Grok 3 is currently sat at the top of the LLM Chatbot Arena (across all of their categories) so it's doing very well based on vibes for the voters there.
Recent articles
- Meta's new model is Muse Spark, and meta.ai chat has some interesting tools - 8th April 2026
- Anthropic's Project Glasswing - restricting Claude Mythos to security researchers - sounds necessary to me - 7th April 2026
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026