OpenAI DevDay: Let’s build developer tools, not digital God
2nd October 2024
I had a fun time live blogging OpenAI DevDay yesterday—I’ve now shared notes about the live blogging system I threw other in a hurry on the day (with assistance from Claude and GPT-4o). Now that the smoke has settled a little, here are my impressions from the event.
- Compared to last year
- Prompt caching, aka the big price drop
- GPT-4o audio via the new WebSocket Realtime API
- Model distillation is fine-tuning made much easier
- Let’s build developer tools, not digital God
Compared to last year
Comparison with the first DevDay in November 2023 are unavoidable. That event was much more keynote-driven: just in the keynote OpenAI released GPT-4 vision, and Assistants, and GPTs, and GPT-4 Turbo (with a massive price drop), and their text-to-speech API. It felt more like a launch-focused product event than something explicitly for developers.
This year was different. Media weren’t invited, there was no livestream, Sam Altman didn’t present the opening keynote (he was interviewed at the end of the day instead) and the new features, while impressive, were not as abundant.
Several features were released in the last few months that could have been saved for DevDay: GPT-4o mini and the o1 model family are two examples. I’m personally happy that OpenAI are shipping features like that as they become ready rather than holding them back for an event.
I’m a bit surprised they didn’t talk about Whisper Turbo at the conference though, released just the day before—especially since that’s one of the few pieces of technology they release under an open source (MIT) license.
This was clearly intended as an event by developers, for developers. If you don’t build software on top of OpenAI’s platform there wasn’t much to catch your attention here.
As someone who does build software on top of OpenAI, there was a ton of valuable and interesting stuff.
Prompt caching, aka the big price drop
I was hoping we might see a price drop, seeing as there’s an ongoing pricing war between Gemini, Anthropic and OpenAI. We got one in an interesting shape: a 50% discount on input tokens for prompts with a shared prefix.
This isn’t a new idea: both Google Gemini and Claude offer a form of prompt caching discount, if you configure them correctly and make smart decisions about when and how the cache should come into effect.
The difference here is that OpenAI apply the discount automatically:
API calls to supported models will automatically benefit from Prompt Caching on prompts longer than 1,024 tokens. The API caches the longest prefix of a prompt that has been previously computed, starting at 1,024 tokens and increasing in 128-token increments. If you reuse prompts with common prefixes, we will automatically apply the Prompt Caching discount without requiring you to make any changes to your API integration.
50% off repeated long prompts is a pretty significant price reduction!
Anthropic’s Claude implementation saves more money: 90% off rather than 50%—but is significantly more work to put into play.
Gemini’s caching requires you to pay per hour to keep your cache warm which makes it extremely difficult to effectively build against in comparison to the other two.
It’s worth noting that OpenAI are not the first company to offer automated caching discounts: DeepSeek have offered that through their API for a few months.
GPT-4o audio via the new WebSocket Realtime API
Absolutely the biggest announcement of the conference: the new Realtime API is effectively the API version of ChatGPT advanced voice mode, a user-facing feature that finally rolled out to everyone just a week ago.
This means we can finally tap directly into GPT-4o’s multimodal audio support: we can send audio directly into the model (without first transcribing it to text via something like Whisper), and we can have it directly return speech without needing to run a separate text-to-speech model.
The way they chose to expose this is interesting: it’s not (yet) part of their existing chat completions API, instead using an entirely new API pattern built around WebSockets.
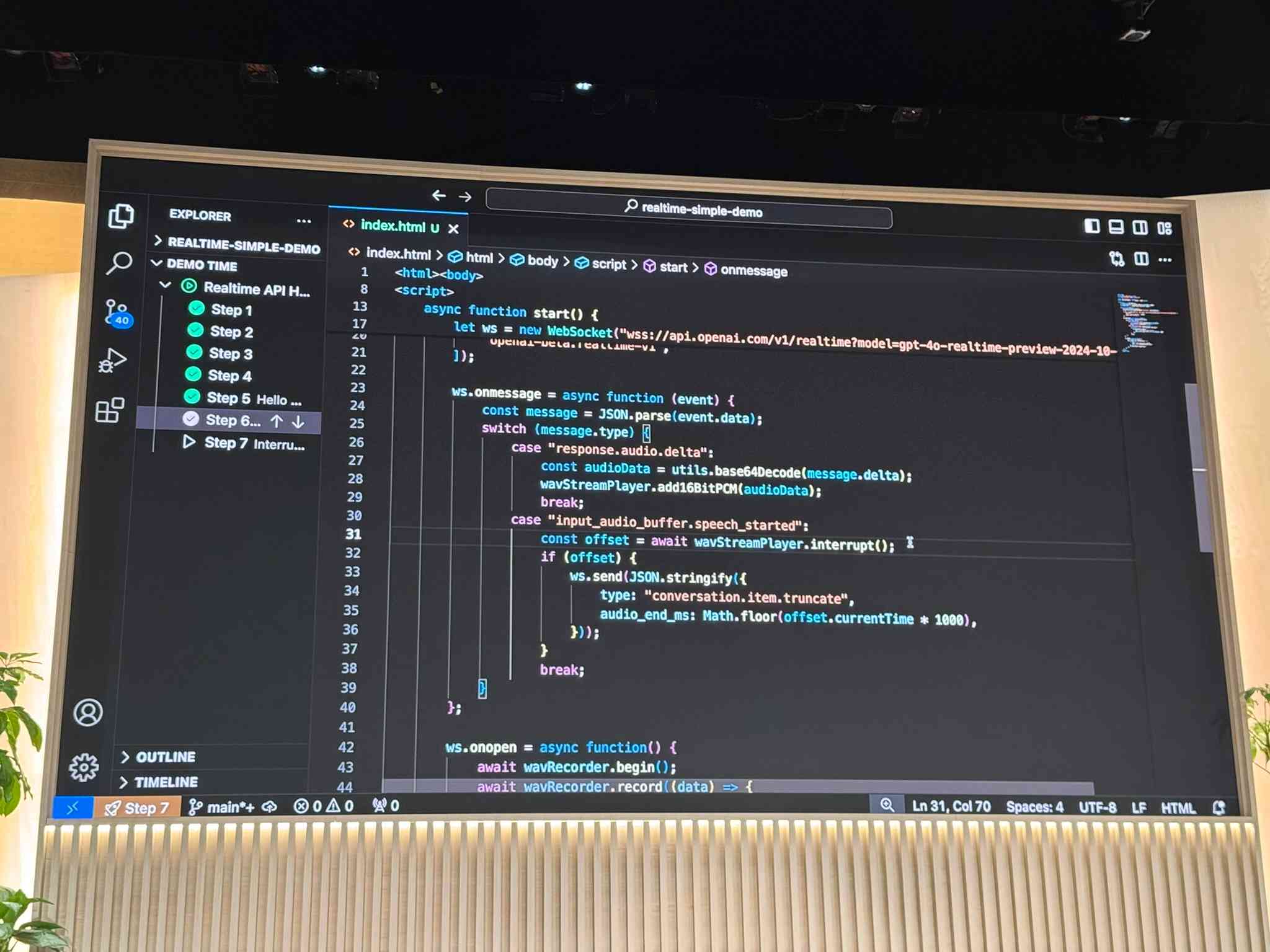
They designed it like that because they wanted it to be as realtime as possible: the API lets you constantly stream audio and text in both directions, and even supports allowing users to speak over and interrupt the model!
So far the Realtime API supports text, audio and function call / tool usage—but doesn’t (yet) support image input (I’ve been assured that’s coming soon). The combination of audio and function calling is super exciting alone though—several of the demos at DevDay used these to build fun voice-driven interactive web applications.
I like this WebSocket-focused API design a lot. My only hesitation is that, since an API key is needed to open a WebSocket connection, actually running this in production involves spinning up an authenticating WebSocket proxy. I hope OpenAI can provide a less code-intensive way of solving this in the future.
Code they showed during the event demonstrated using the native browser WebSocket class directly, but I can’t find those code examples online now. I hope they publish it soon. For the moment the best things to look at are the openai-realtime-api-beta and openai-realtime-console repositories.
The new playground/realtime debugging tool—the OpenAI playground for the Realtime API—is a lot of fun to try out too.
Model distillation is fine-tuning made much easier
The other big developer-facing announcements were around model distillation, which to be honest is more of a usability enhancement and minor rebranding of their existing fine-tuning features.
OpenAI have offered fine-tuning for a few years now, most recently against their GPT-4o and GPT-4o mini models. They’ve practically been begging people to try it out, offering generous free tiers in previous months:
Today [August 20th 2024] we’re launching fine-tuning for GPT-4o, one of the most requested features from developers. We are also offering 1M training tokens per day for free for every organization through September 23.
That free offer has now been extended. A footnote on the pricing page today:
Fine-tuning for GPT-4o and GPT-4o mini is free up to a daily token limit through October 31, 2024. For GPT-4o, each qualifying org gets up to 1M complimentary training tokens daily and any overage will be charged at the normal rate of $25.00/1M tokens. For GPT-4o mini, each qualifying org gets up to 2M complimentary training tokens daily and any overage will be charged at the normal rate of $3.00/1M tokens
The problem with fine-tuning is that it’s really hard to do effectively. I tried it a couple of years ago myself against GPT-3—just to apply tags to my blog content—and got disappointing results which deterred me from spending more money iterating on the process.
To fine-tune a model effectively you need to gather a high quality set of examples and you need to construct a robust set of automated evaluations. These are some of the most challenging (and least well understood) problems in the whole nascent field of prompt engineering.
OpenAI’s solution is a bit of a rebrand. “Model distillation” is a form of fine-tuning where you effectively teach a smaller model how to do a task based on examples generated by a larger model. It’s a very effective technique. Meta recently boasted about how their impressive Llama 3.2 1B and 3B models were “taught” by their larger models:
[...] powerful teacher models can be leveraged to create smaller models that have improved performance. We used two methods—pruning and distillation—on the 1B and 3B models, making them the first highly capable lightweight Llama models that can fit on devices efficiently.
Yesterday OpenAI released two new features to help developers implement this pattern.
The first is stored completions. You can now pass a “store”: true parameter to have OpenAI permanently store your prompt and its response in their backend, optionally with your own additional tags to help you filter the captured data later.
You can view your stored completions at platform.openai.com/chat-completions.
I’ve been doing effectively the same thing with my LLM command-line tool logging to a SQLite database for over a year now. It’s a really productive pattern.
OpenAI pitch stored completions as a great way to collect a set of training data from their large models that you can later use to fine-tune (aka distill into) a smaller model.
The second, even more impactful feature, is evals. You can now define and run comprehensive prompt evaluations directly inside the OpenAI platform.
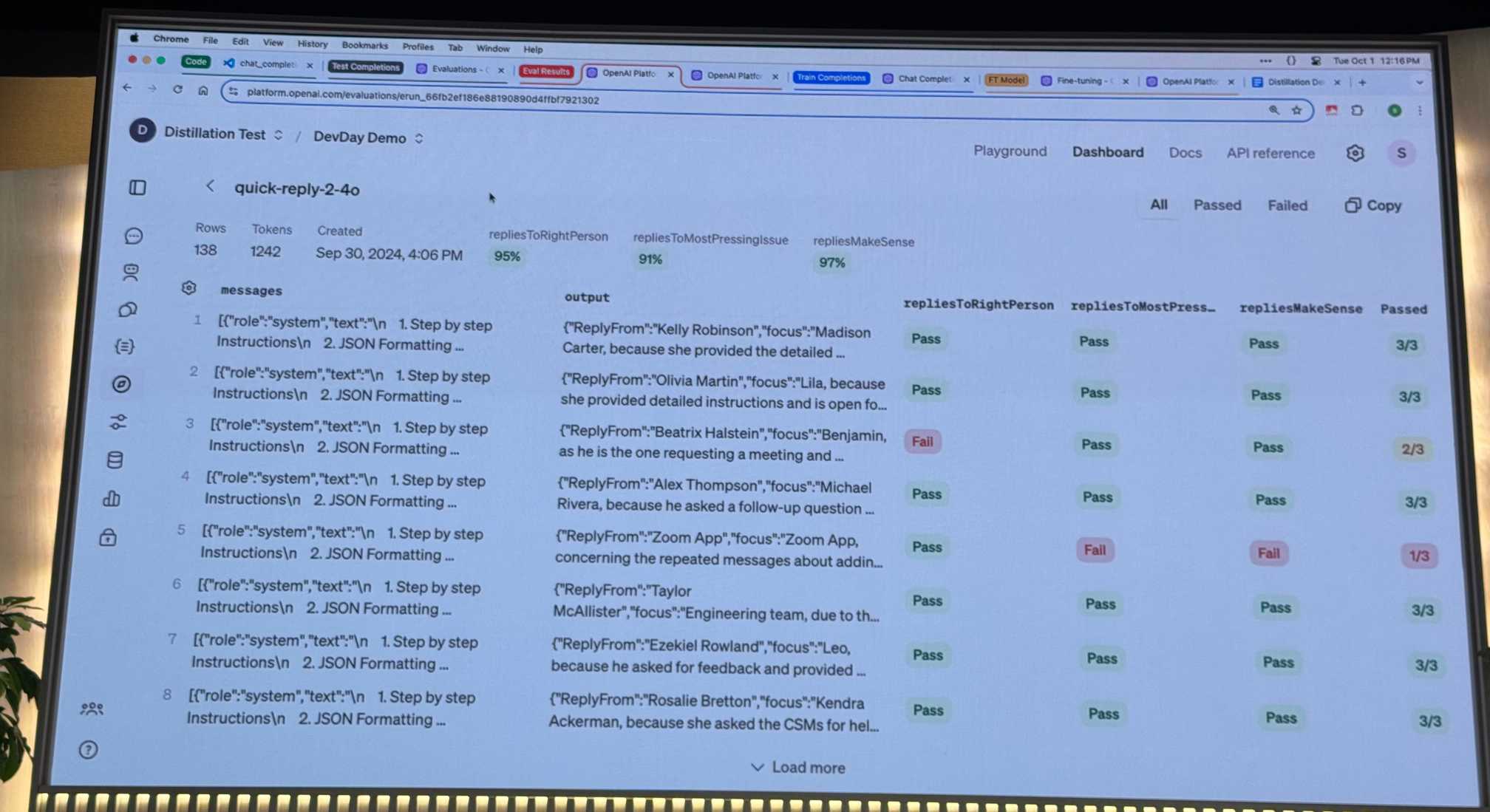
OpenAI’s new eval tool competes directly with a bunch of existing startups—I’m quite glad I didn’t invest much effort in this space myself!
The combination of evals and stored completions certainly seems like it should make the challenge of fine-tuning a custom model far more tractable.
The other fine-tuning announcement, greeted by applause in the room, was fine-tuning for images. This has always felt like one of the most obviously beneficial fine-tuning use-cases for me, since it’s much harder to get great image recognition results from sophisticated prompting alone.
From a strategic point of view this makes sense as well: it has become increasingly clear over the last year that many prompts are inherently transferable between models—it’s very easy to take an application with prompts designed for GPT-4o and switch it to Claude or Gemini or Llama with few if any changes required.
A fine-tuned model on the OpenAI platform is likely to be far more sticky.
Let’s build developer tools, not digital God
In the last session of the day I furiously live blogged the Fireside Chat between Sam Altman and Kevin Weil, trying to capture as much of what they were saying as possible.
A bunch of the questions were about AGI. I’m personally quite uninterested in AGI: it’s always felt a bit too much like science fiction for me. I want useful AI-driven tools that help me solve the problems I want to solve.
One point of frustration: Sam referenced OpenAI’s five-level framework a few times. I found several news stories (many paywalled—here’s one that isn’t) about it but I can’t find a definitive URL on an OpenAI site that explains what it is! This is why you should always Give people something to link to so they can talk about your features and ideas.
Both Sam and Kevin seemed to be leaning away from AGI as a term. From my live blog notes (which paraphrase what was said unless I use quotation marks):
Sam says they’re trying to avoid the term now because it has become so over-loaded. Instead they think about their new five steps framework.
“I feel a little bit less certain on that” with respect to the idea that an AGI will make a new scientific discovery.
Kevin: “There used to be this idea of AGI as a binary thing [...] I don’t think that’s how think about it any more”.
Sam: Most people looking back in history won’t agree when AGI happened. The turing test wooshed past and nobody cared.
I for one found this very reassuring. The thing I want from OpenAI is more of what we got yesterday: I want platform tools that I can build unique software on top of which I colud not have built previously.
If the ongoing, well-documented internal turmoil at OpenAI from the last year is a result of the organization reprioritizing towards shipping useful, reliable tools for developers (and consumers) over attempting to build a digital God, then I’m all for it.
And yet… OpenAI just this morning finalized a raise of another $6.5 billion dollars at a staggering $157 billion post-money valuation. That feels more like a digital God valuation to me than a platform for developers in an increasingly competitive space.
More recent articles
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026
- Highlights from my conversation about agentic engineering on Lenny's Podcast - 2nd April 2026
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026