20th December 2024 - Link Blog
OpenAI o3 breakthrough high score on ARC-AGI-PUB. François Chollet is the co-founder of the ARC Prize and had advanced access to today's o3 results. His article here is the most insightful coverage I've seen of o3, going beyond just the benchmark results to talk about what this all means for the field in general.
One fascinating detail: it cost $6,677 to run o3 in "high efficiency" mode against the 400 public ARC-AGI puzzles for a score of 82.8%, and an undisclosed amount of money to run the "low efficiency" mode model to score 91.5%. A note says:
o3 high-compute costs not available as pricing and feature availability is still TBD. The amount of compute was roughly 172x the low-compute configuration.
So we can get a ballpark estimate here in that 172 * $6,677 = $1,148,444!
Here's how François explains the likely mechanisms behind o3, which reminds me of how a brute-force chess computer might work.
For now, we can only speculate about the exact specifics of how o3 works. But o3's core mechanism appears to be natural language program search and execution within token space – at test time, the model searches over the space of possible Chains of Thought (CoTs) describing the steps required to solve the task, in a fashion perhaps not too dissimilar to AlphaZero-style Monte-Carlo tree search. In the case of o3, the search is presumably guided by some kind of evaluator model. To note, Demis Hassabis hinted back in a June 2023 interview that DeepMind had been researching this very idea – this line of work has been a long time coming.
So while single-generation LLMs struggle with novelty, o3 overcomes this by generating and executing its own programs, where the program itself (the CoT) becomes the artifact of knowledge recombination. Although this is not the only viable approach to test-time knowledge recombination (you could also do test-time training, or search in latent space), it represents the current state-of-the-art as per these new ARC-AGI numbers.
Effectively, o3 represents a form of deep learning-guided program search. The model does test-time search over a space of "programs" (in this case, natural language programs – the space of CoTs that describe the steps to solve the task at hand), guided by a deep learning prior (the base LLM). The reason why solving a single ARC-AGI task can end up taking up tens of millions of tokens and cost thousands of dollars is because this search process has to explore an enormous number of paths through program space – including backtracking.
I'm not sure if o3 (and o1 and similar models) even qualifies as an LLM any more - there's clearly a whole lot more going on here than just next-token prediction.
On the question of if o3 should qualify as AGI (whatever that might mean):
Passing ARC-AGI does not equate to achieving AGI, and, as a matter of fact, I don't think o3 is AGI yet. o3 still fails on some very easy tasks, indicating fundamental differences with human intelligence.
Furthermore, early data points suggest that the upcoming ARC-AGI-2 benchmark will still pose a significant challenge to o3, potentially reducing its score to under 30% even at high compute (while a smart human would still be able to score over 95% with no training).
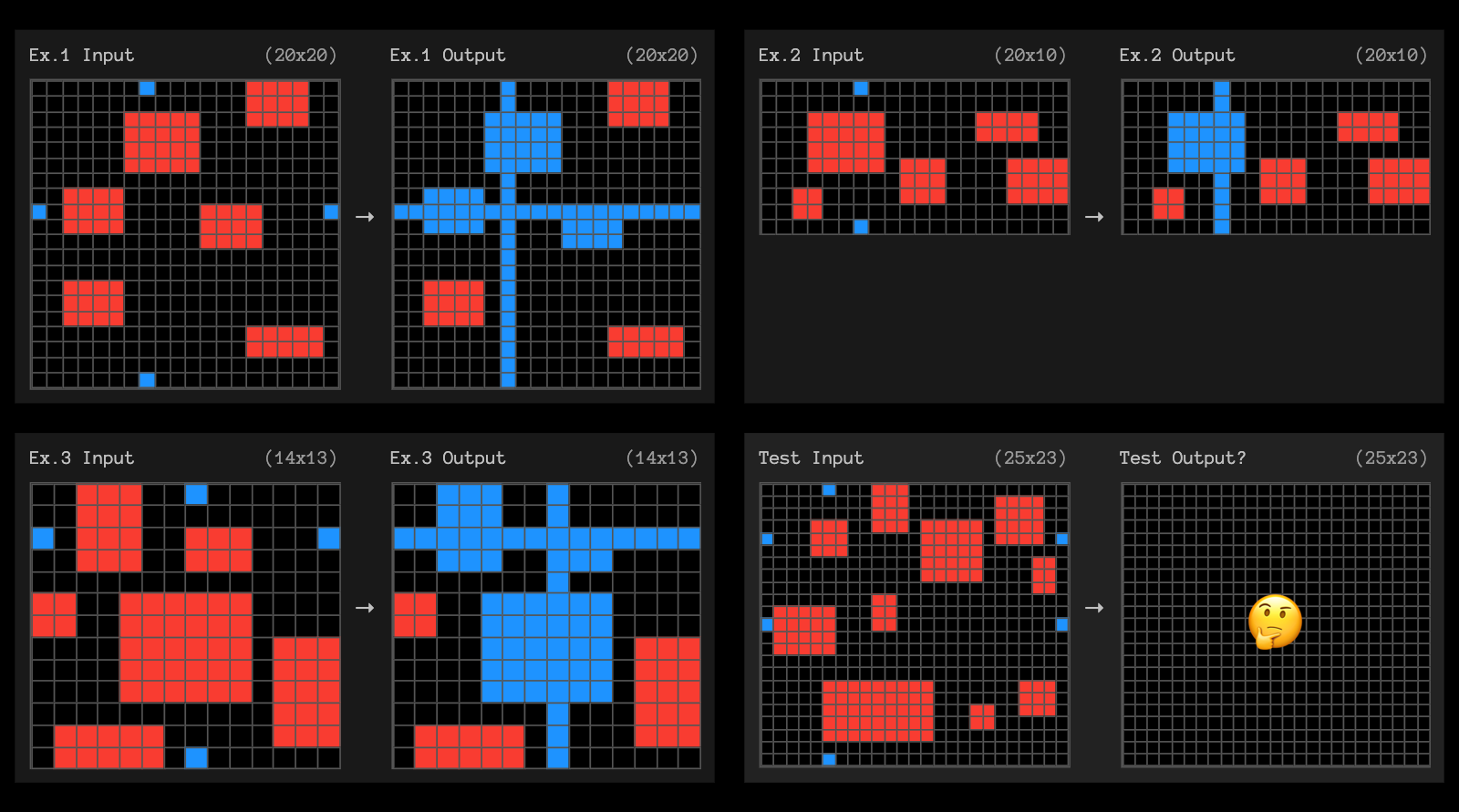
The post finishes with examples of the puzzles that o3 didn't manage to solve, including this one which reassured me that I can still solve at least some puzzles that couldn't be handled with thousands of dollars of GPU compute!
Recent articles
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026
- Highlights from my conversation about agentic engineering on Lenny's Podcast - 2nd April 2026
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026