Live blog: the 12th day of OpenAI—“Early evals for OpenAI o3”
20th December 2024
It’s the final day of OpenAI’s 12 Days of OpenAI launch series, and since I built a live blogging system a couple of months ago I’ve decided to roll it out again to provide live commentary during the half hour event, which kicks off at 10am San Francisco time.
Here’s the video on YouTube.
09:34 Stream starts in about 25 minutes.
09:44 I'll be honest, I haven't been paying close attention to the rumors about today - mainly because I can't evaluate if they're credible (based on insider information) or just excitable hype. The main themes I've seen are a possible o3 model (skipping o2 because that's already a global brand name) or a GPT-4.5.
09:48 The source of that o3 rumor is this story on The Information from yesterday: OpenAI Preps ‘o3’ Reasoning Model - you'll have to register for an account to read it.
09:49 Plus Sam Altman tweeted this last night:
fine one clue
should have said oh oh oh
09:51 In case you missed it, here's my roundup of the LLM announcements in December 2024 so far. They were a lot.
09:53 @OpenAI:
Day 12: Early evals for OpenAI o3 (yes, we skipped a number)
09:55 The fact that this is now titled "Early evals for OpenAI o3" seems to indicate that we won't get a new model to try out ourselves, which is a little disappointing.
09:57 Alex Volkov is running a Twitter Space watch party with live commentary after the event.
10:00 Since today is about o3, it's worth digging a little more into this new but fascinating field of inference scaling models. o1-mini and o1-preview were the first of these, all the way back in September. Since then we've seen similar models from Qwen (QwQ), DeepSeek (DeepSeek-R1-Lite-Preview) and Google (Gemini 2.0 Flash Thinking).
10:01 The stream just started. Sam Altman admits to OpenAI being "really bad at names"!
10:01 O3 will be available for "public safety testing" starting today.
10:01 ... which DOES mean some element of public access, for "researchers who want to help us test".
10:02 Now hearing from Mark Chen, SVP of Research at OpenAI.
10:03 I think this is Mark's competitive programming profile.
10:04 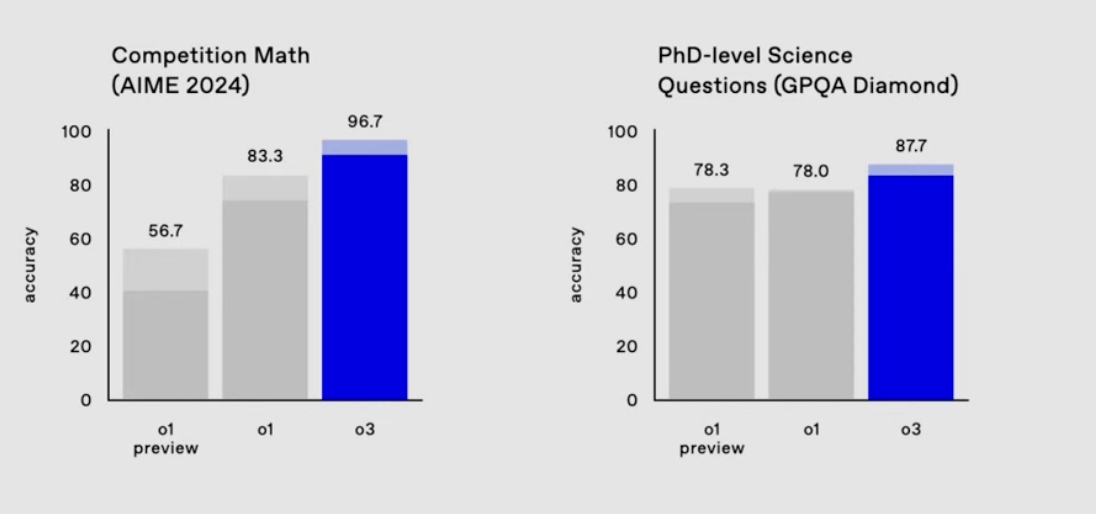
10:05 Lots of benchmark talk - I guess that was hinted at by the title of the session, "Early evals for OpenAI o3".
10:05 Mark: "We have one more surprise for you" - bringing in Greg Kamradt of the foundation behind the ARC benchmark, unbeaten for five years.
10:07 Greg: "Today we have a new state-of-the-art score to announce".
The ARC AGI test is all about input and output examples. It's basically a collection of visual puzzles.
Here's the ARC AGI site.
10:08
o3 has scored "a new state of the art score that we have veriified".
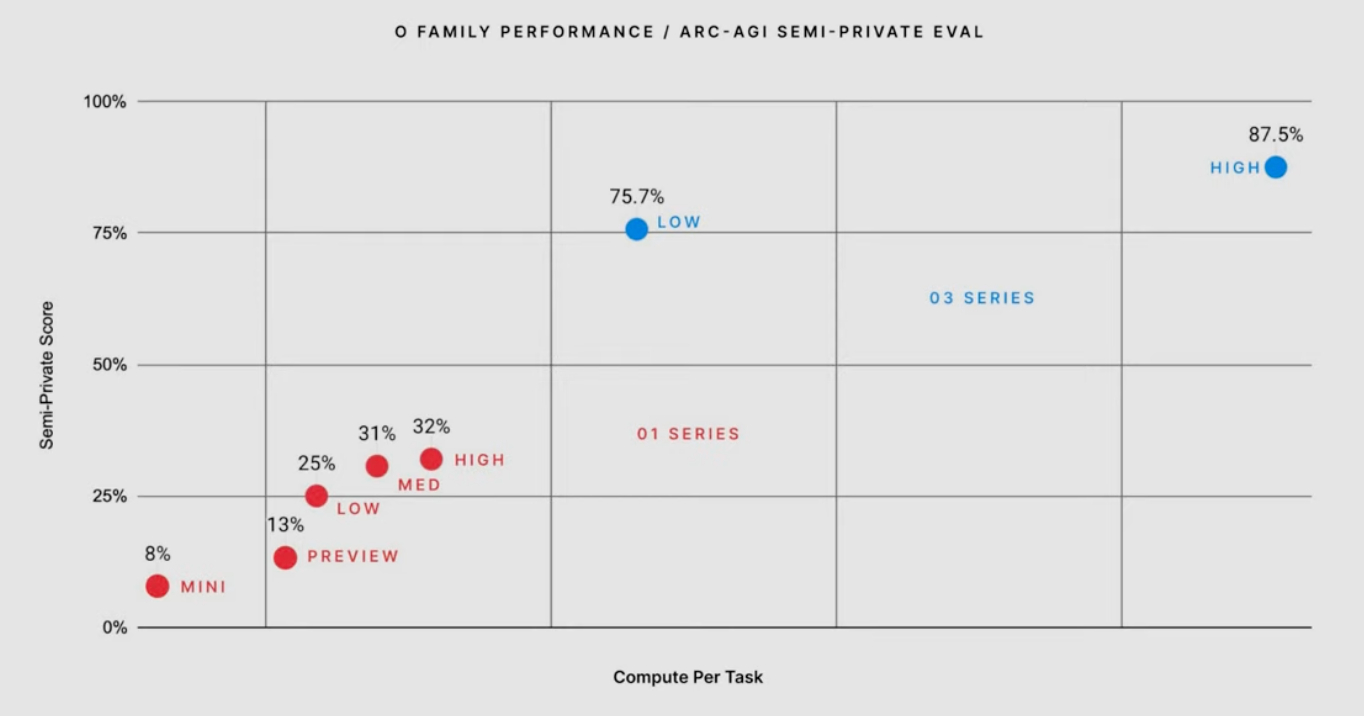
10:09 Greg also says this is the first time a model has beat the top result for a human.
10:09 Greg: "We need more enduring benchmarks like ARC AGI" - partnering with OpenAI to develop future benchmarks.
10:10 Next up: o3-mini.
10:11 Now hearing from OpenAI researcher Hongyu Ren, who trained o3-mini. It's not available to general users today but is now open to safety researchers.
10:11 o3-mini will support low, medium and high reasoning effort - similar to o1 in the OpenAI API.
10:12 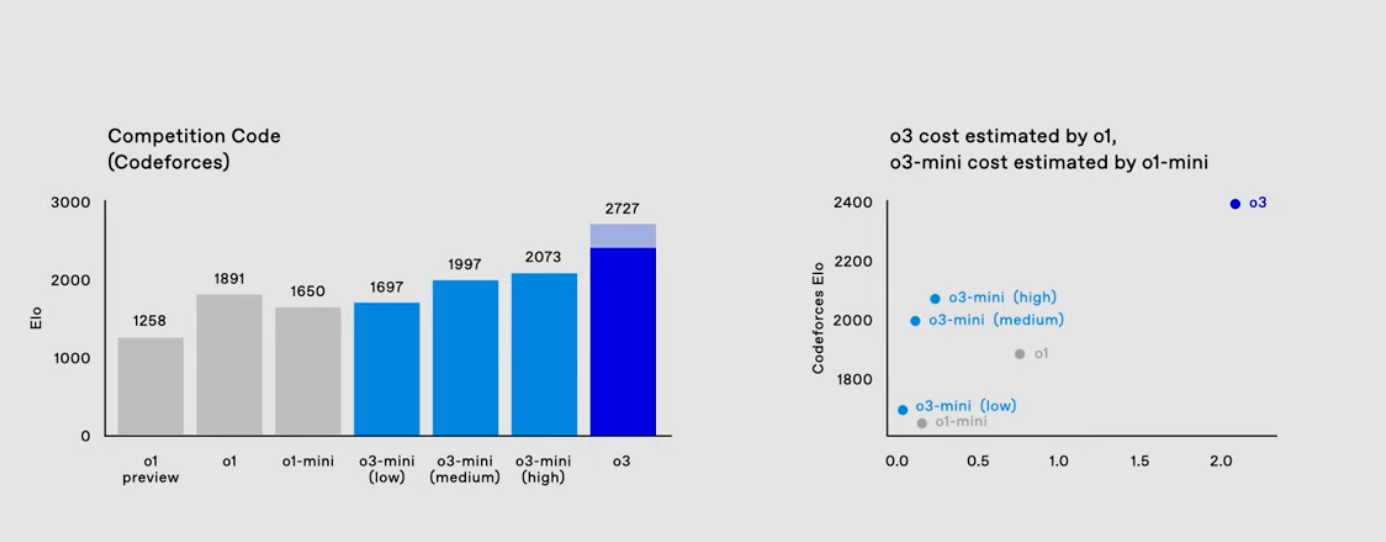
10:12 Huge cost to performance gain over o1 - same trend we're seeing across most of the models vendors right now (Google Gemini, AWS Nova etc).
10:14 For this demo - where o3-mini is writing Python code - they're generating Python, manually copying and pasting it back to a terminal, then running it. They could do with their own version of Claude's MCP!
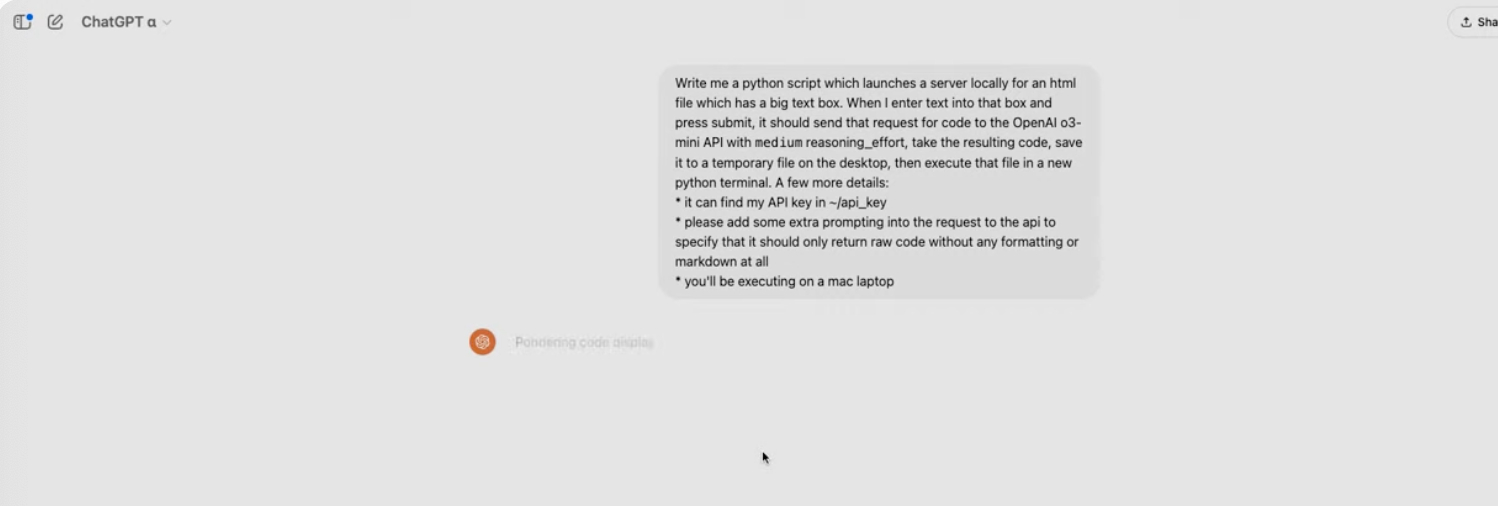
10:16 I captured this snippet of the more advanced prompt they are trying:
10:17 So they asked the model to write a script to evaluate itself using a code generator/executor UI that the model itself was used to create.
10:17 "The model is also a pretty good math model". o3-mini (low) is similar to o1-mini, and o3-mini (high) matches current o1.
10:19 And the most interesting benchmarks, covering practical things like function calling and structured outputs:
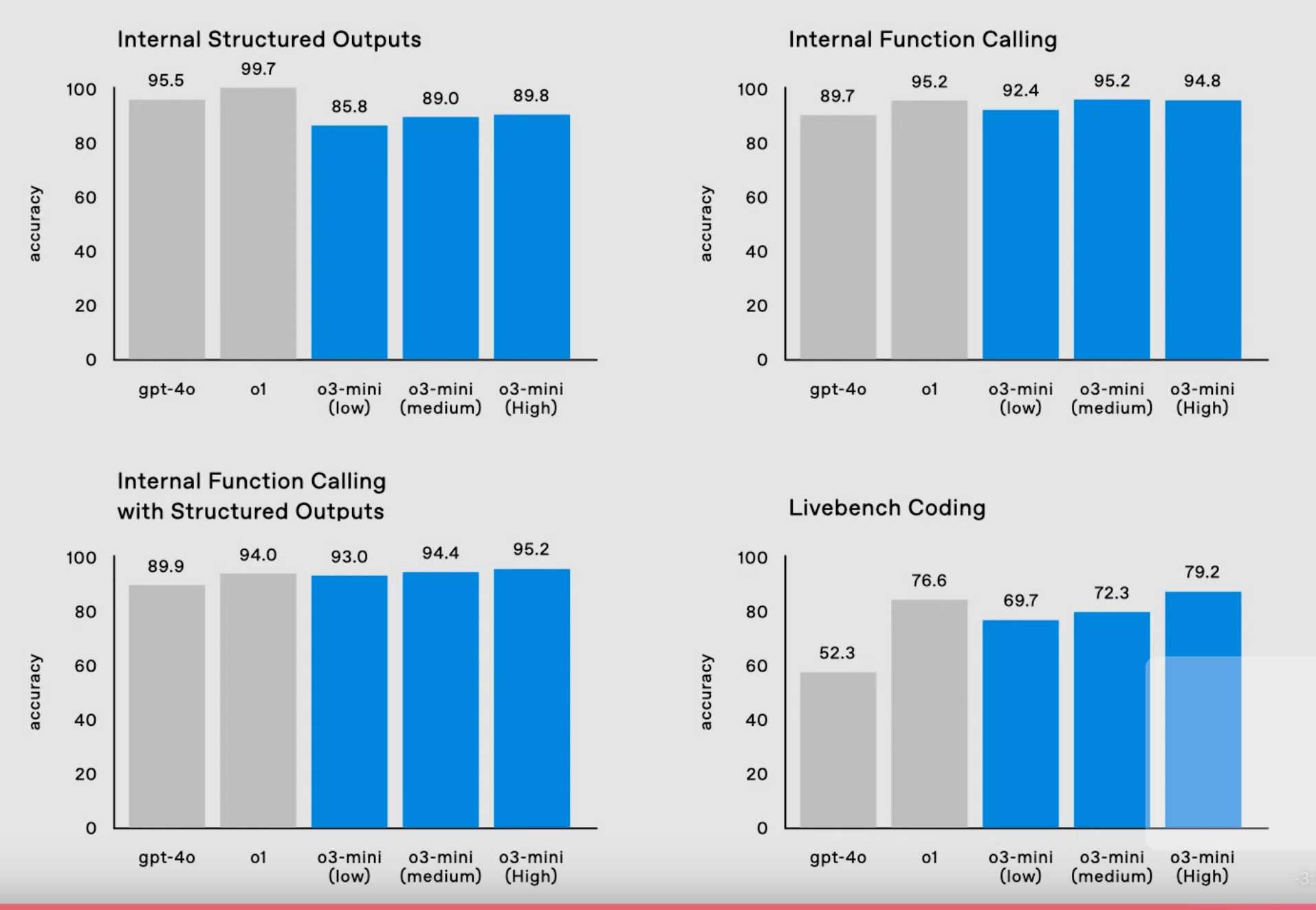
10:19 External safety testing is starting for o3-mini (and soon for full o3). There will be a form on OpenAI's site for this, applications close on January 10th.
10:21 Now talking about deliberative alignment. Trying to reason if a prompt is "safe" - is the user trying to trick it? Sounds very relevant to prompt injection.
10:21 
10:22
Sam: "We plan to launch o3-mini around the end of January, and full o3 shortly after that".
Live stream ends with "Merry Christmas" and applause and cheers from the background.
10:23 It's notable that the term "AGI" wasn't mentioned once (aside from being the name of the ARC benchmark).
10:24 OK, I'm finished here. Thanks for following along.
11:11 François Chollet on the ARC Prize blog: OpenAI o3 breakthrough high score on ARC-AGI-PUB. This is the most detailed coverage I've seen of o3, discussing the model beyond just the benchmark results. I published my own notes on this piece here.
More recent articles
- Highlights from my conversation about agentic engineering on Lenny's Podcast - 2nd April 2026
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026
- Vibe coding SwiftUI apps is a lot of fun - 27th March 2026