16th August 2024 - Link Blog
LLMs are bad at returning code in JSON (via) Paul Gauthier's Aider is a terminal-based coding assistant which works against multiple different models. As part of developing the project Paul runs extensive benchmarks, and his latest shows an interesting result: LLMs are slightly less reliable at producing working code if you request that code be returned as part of a JSON response.
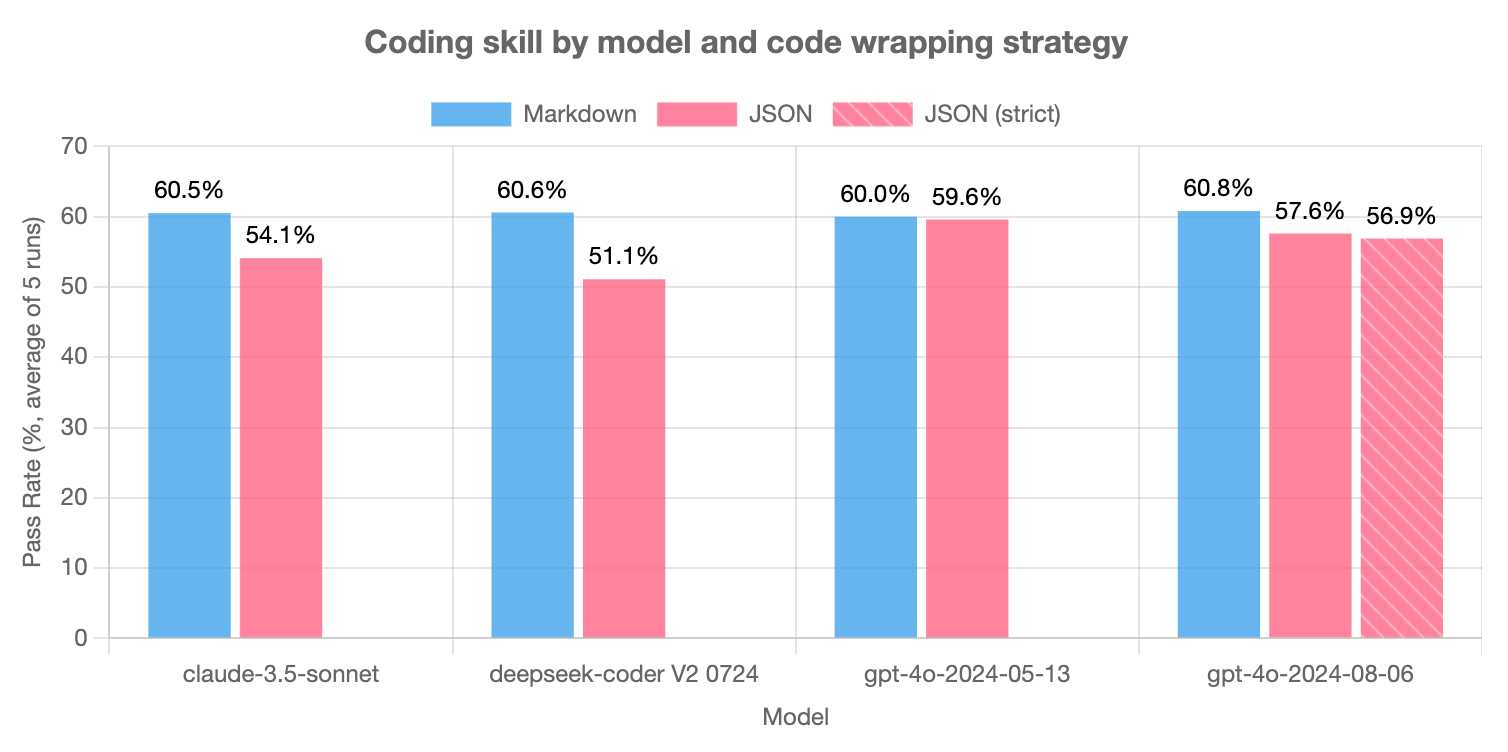
The May release of GPT-4o is the closest to a perfect score - the August appears to have regressed slightly, and the new structured output mode doesn't help and could even make things worse (though that difference may not be statistically significant).
Paul recommends using Markdown delimiters here instead, which are less likely to introduce confusing nested quoting issues.
Recent articles
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026
- Profiling Hacker News users based on their comments - 21st March 2026
- Thoughts on OpenAI acquiring Astral and uv/ruff/ty - 19th March 2026