9th February 2026 - Link Blog
Structured Context Engineering for File-Native Agentic Systems (via) New paper by Damon McMillan exploring challenging LLM context tasks involving large SQL schemas (up to 10,000 tables) across different models and file formats:
Using SQL generation as a proxy for programmatic agent operations, we present a systematic study of context engineering for structured data, comprising 9,649 experiments across 11 models, 4 formats (YAML, Markdown, JSON, Token-Oriented Object Notation [TOON]), and schemas ranging from 10 to 10,000 tables.
Unsurprisingly, the biggest impact was the models themselves - with frontier models (Opus 4.5, GPT-5.2, Gemini 2.5 Pro) beating the leading open source models (DeepSeek V3.2, Kimi K2, Llama 4).
Those frontier models benefited from filesystem based context retrieval, but the open source models had much less convincing results with those, which reinforces my feeling that the filesystem coding agent loops aren't handled as well by open weight models just yet. The Terminal Bench 2.0 leaderboard is still dominated by Anthropic, OpenAI and Gemini.
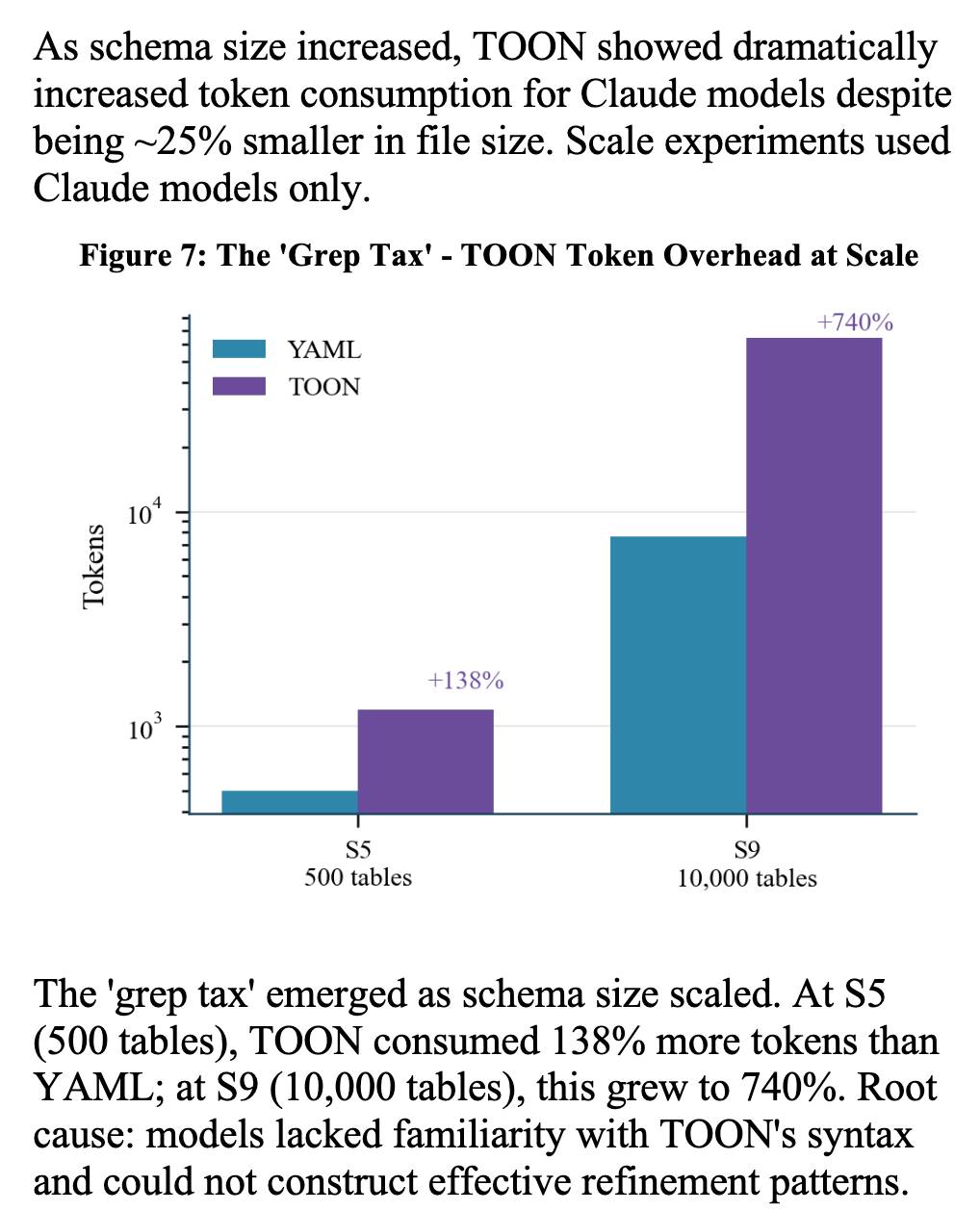
The "grep tax" result against TOON was an interesting detail. TOON is meant to represent structured data in as few tokens as possible, but it turns out the model's unfamiliarity with that format led to them spending significantly more tokens over multiple iterations trying to figure it out:
Recent articles
- Meta's new model is Muse Spark, and meta.ai chat has some interesting tools - 8th April 2026
- Anthropic's Project Glasswing - restricting Claude Mythos to security researchers - sounds necessary to me - 7th April 2026
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026