Claude Opus 4.5, and why evaluating new LLMs is increasingly difficult
24th November 2025
Anthropic released Claude Opus 4.5 this morning, which they call “best model in the world for coding, agents, and computer use”. This is their attempt to retake the crown for best coding model after significant challenges from OpenAI’s GPT-5.1-Codex-Max and Google’s Gemini 3, both released within the past week!
The core characteristics of Opus 4.5 are a 200,000 token context (same as Sonnet), 64,000 token output limit (also the same as Sonnet), and a March 2025 “reliable knowledge cutoff” (Sonnet 4.5 is January, Haiku 4.5 is February).
The pricing is a big relief: $5/million for input and $25/million for output. This is a lot cheaper than the previous Opus at $15/$75 and keeps it a little more competitive with the GPT-5.1 family ($1.25/$10) and Gemini 3 Pro ($2/$12, or $4/$18 for >200,000 tokens). For comparison, Sonnet 4.5 is $3/$15 and Haiku 4.5 is $1/$5.
The Key improvements in Opus 4.5 over Opus 4.1 document has a few more interesting details:
- Opus 4.5 has a new effort parameter which defaults to high but can be set to medium or low for faster responses.
- The model supports enhanced computer use, specifically a
zoomtool which you can provide to Opus 4.5 to allow it to request a zoomed in region of the screen to inspect. - "Thinking blocks from previous assistant turns are preserved in model context by default"—apparently previous Anthropic models discarded those.
I had access to a preview of Anthropic’s new model over the weekend. I spent a bunch of time with it in Claude Code, resulting in a new alpha release of sqlite-utils that included several large-scale refactorings—Opus 4.5 was responsible for most of the work across 20 commits, 39 files changed, 2,022 additions and 1,173 deletions in a two day period. Here’s the Claude Code transcript where I had it help implement one of the more complicated new features.
It’s clearly an excellent new model, but I did run into a catch. My preview expired at 8pm on Sunday when I still had a few remaining issues in the milestone for the alpha. I switched back to Claude Sonnet 4.5 and... kept on working at the same pace I’d been achieving with the new model.
With hindsight, production coding like this is a less effective way of evaluating the strengths of a new model than I had expected.
I’m not saying the new model isn’t an improvement on Sonnet 4.5—but I can’t say with confidence that the challenges I posed it were able to identify a meaningful difference in capabilities between the two.
This represents a growing problem for me. My favorite moments in AI are when a new model gives me the ability to do something that simply wasn’t possible before. In the past these have felt a lot more obvious, but today it’s often very difficult to find concrete examples that differentiate the new generation of models from their predecessors.
Google’s Nano Banana Pro image generation model was notable in that its ability to render usable infographics really does represent a task at which previous models had been laughably incapable.
The frontier LLMs are a lot harder to differentiate between. Benchmarks like SWE-bench Verified show models beating each other by single digit percentage point margins, but what does that actually equate to in real-world problems that I need to solve on a daily basis?
And honestly, this is mainly on me. I’ve fallen behind on maintaining my own collection of tasks that are just beyond the capabilities of the frontier models. I used to have a whole bunch of these but they’ve fallen one-by-one and now I’m embarrassingly lacking in suitable challenges to help evaluate new models.
I frequently advise people to stash away tasks that models fail at in their notes so they can try them against newer models later on—a tip I picked up from Ethan Mollick. I need to double-down on that advice myself!
I’d love to see AI labs like Anthropic help address this challenge directly. I’d like to see new model releases accompanied by concrete examples of tasks they can solve that the previous generation of models from the same provider were unable to handle.
“Here’s an example prompt which failed on Sonnet 4.5 but succeeds on Opus 4.5” would excite me a lot more than some single digit percent improvement on a benchmark with a name like MMLU or GPQA Diamond.
In the meantime, I’m just gonna have to keep on getting them to draw pelicans riding bicycles. Here’s Opus 4.5 (on its default “high” effort level):

It did significantly better on the new more detailed prompt:

Here’s that same complex prompt against Gemini 3 Pro and against GPT-5.1-Codex-Max-xhigh.
Still susceptible to prompt injection
From the safety section of Anthropic’s announcement post:
With Opus 4.5, we’ve made substantial progress in robustness against prompt injection attacks, which smuggle in deceptive instructions to fool the model into harmful behavior. Opus 4.5 is harder to trick with prompt injection than any other frontier model in the industry:
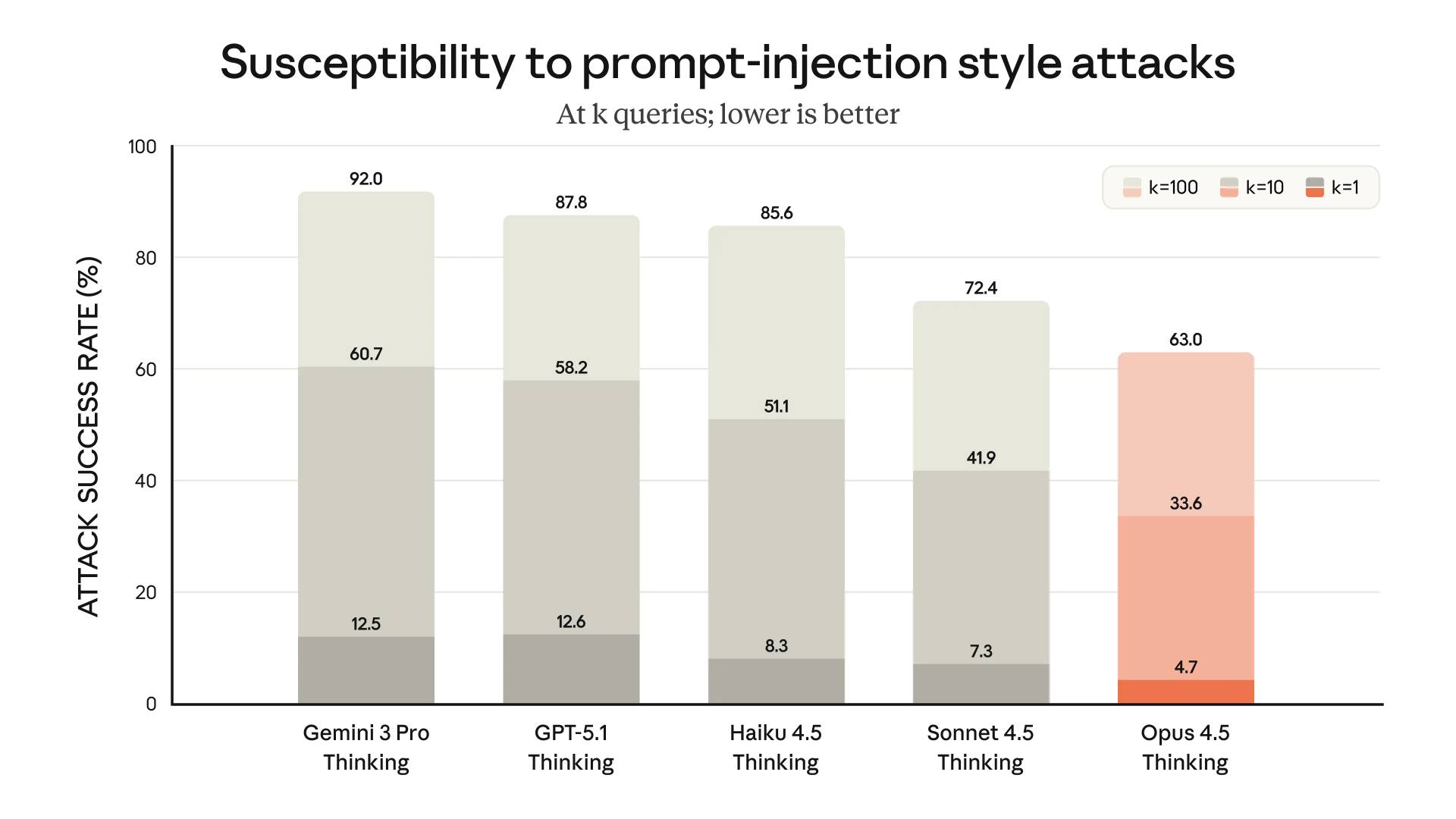
On the one hand this looks great, it’s a clear improvement over previous models and the competition.
What does the chart actually tell us though? It tells us that single attempts at prompt injection still work 1/20 times, and if an attacker can try ten different attacks that success rate goes up to 1/3!
I still don’t think training models not to fall for prompt injection is the way forward here. We continue to need to design our applications under the assumption that a suitably motivated attacker will be able to find a way to trick the models.
More recent articles
- Perhaps not Boring Technology after all - 9th March 2026
- Can coding agents relicense open source through a “clean room” implementation of code? - 5th March 2026
- Something is afoot in the land of Qwen - 4th March 2026