Qwen 3 offers a case study in how to effectively release a model
29th April 2025
Alibaba’s Qwen team released the hotly anticipated Qwen 3 model family today. The Qwen models are already some of the best open weight models—Apache 2.0 licensed and with a variety of different capabilities (including vision and audio input/output).
Qwen 3 is text input/output only for the moment and comes in an exciting range of different shapes and sizes: 32B, 14B, 8B, 4B, 1.7B, and 0.6B models. The 4B and up models all have 131,072 token context windows (extended from 32k using YaRN)—0.6B, and 1.7B are 32,768.
This covers the full spectrum of sizes that I generally care about: 0.6B and 1.7B should run fine on an iPhone, and 32B will fit on my 64GB Mac with room to spare for other applications.
Qwen also released two Mixture of Experts models—Qwen3-30B-A3B and Qwen3-235B-A22B. The A stands for “active parameters”—Qwen3-30B-A3B is a 30 billion parameter model that keeps 3 billion active at once, which speeds up inference (I previously said it reduces the memory needed to run the models, but that’s incorrect).
All eight of these models are released under the Apache 2.0 license.
Qwen describe these as “hybrid thinking” models—every one of them is capable of the “reason step by step” trick before they deliver their final answer. In my experiments so far this presents itself as a <think>...</think> block at the start of the response.
That thinking mode can be turned on and off by including special /think and /no_think tokens in the prompt. It’s on by default.
One last interesting snippet from the announcement:
We have optimized the Qwen3 models for coding and agentic capabilities, and also we have strengthened the support of MCP as well.
This is the first time I’ve seen a model specifically trained for the Model Context Protocol, which was first announced by Anthropic last November.
- Trying out Qwen 3 via Ollama
- A really well coordinated release
- The continuing trend of better models that run on the same hardware
Trying out Qwen 3 via Ollama
Let’s see that in action. I started out with Qwen 32B from Ollama—a 20GB download:
ollama pull qwen3:32bThen I ran a prompt against it using LLM and the llm-ollama plugin:
llm -m qwen3:32b 'Generate an SVG of a pelican riding a bicycle'Here’s the truncated output I got back (you can see the full response in this Gist).
<think>
Okay, the user wants an SVG of a pelican riding a bicycle. Let me start by breaking down the components needed. First, I need to create the pelican. Pelicans have a distinctive beak and pouch, so I’ll need to draw that. Maybe start with an ellipse for the body, then add the beak as a triangle. The wings could be curved shapes on either side.Next, the bicycle. I’ll need two wheels, a frame, handlebars, and pedals. The wheels can be circles with some lines for spokes. The frame connects the wheels, with a seat and handlebars at the front. The pedals are small circles with lines for the crank.
[...]
I think that’s a plan. Now, translate this into SVG code step by step, making sure coordinates and shapes are correctly placed.
</think>Here’s an SVG of a pelican riding a bicycle, created using simple shapes and paths:
<svg viewBox="0 0 200 200" xmlns="http://www.w3.org/2000/svg"> <!-- Bicycle Frame --> <line x1="40" y1="100" x2="120" y2="100" stroke="black" stroke-width="4"/> <line x1="120" y1="100" x2="140" y2="80" stroke="black" stroke-width="4"/> [...] <!-- Bicycle Handlebars --> <rect x="30" y="80" width="20" height="5" fill="#8B4513"/> </svg>This SVG features:
- A basic bicycle frame with two wheels, spokes, and a seat
- A blue pelican with:
- A rounded body and head
- A distinctive yellow beak and orange pouch
- Two wings extending from the body
- Webbed feet wrapped around the bicycle frame
- Simple handlebars at the front of the bicycle
The pelican is positioned sitting on the bicycle seat with wings slightly spread for balance. You can copy this code into an HTML file or SVG editor to view the illustration. The colors use traditional bicycle brown (#8B4513) and a classic blue for the pelican (#4169E1) with gold accents for the beak (#FFD700).
As is often the case with “reasoning” models, reading the reasoning chain is more interesting than the finished result. Here’s what the SVG looks like when you render it:
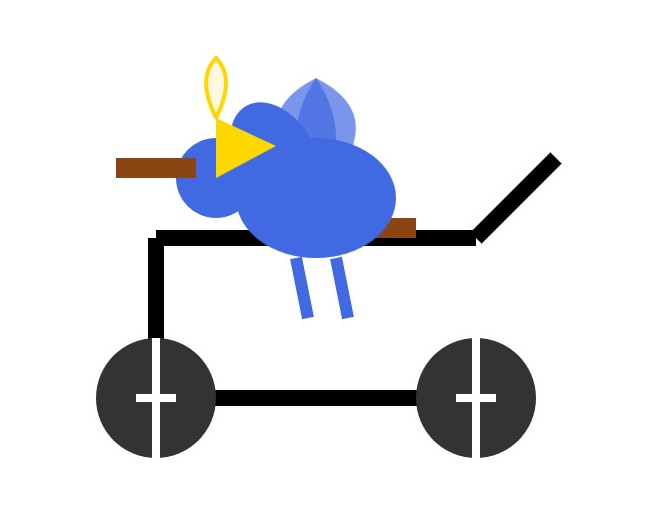
Not the best pelican on a bicycle, but I’ve seen worse!
A really well coordinated release
The thing that stands out most to me about the Qwen 3 release is how well coordinated it was across the LLM ecosystem.
Qwen worked directly with almost all of the popular LLM serving frameworks to ensure that support for the new models was available on day one.
The Qwen 3 README mentions the following projects:
- The Transformers Python library
- ModelScope (effectively the Chinese equivalent of Hugging Face for model distribution)
-
llama.cpp, which added support for the Qwen 3 architecture three weeks ago in version
b5092. - Ollama, with qwen3 out on release day
- LMStudio
- mlx-lm for Apple Silicon—the first commit for Qwen 3 support in MLX showed up in a PR over a month ago.
- The SGLang serving framework
- The popular vLLM engine
- MindIE, which I haven’t heard of before but looks to be a serving framework for Huawei’s Ascend chips (competitive with NVIDIA’s GPUs)
This is an extraordinary level of coordination for a model release! I haven’t seen any other model providers make this level of effort—the usual pattern is to dump a bunch of models on Hugging Face for a single architecture (usually NVIDIA) and then wait for the community to catch up with quantizations and conversions for everything else.
It’s also great to see smaller models that can run on consumer hardware on day one. I think one of the reasons the Llama 4 release a few weeks ago was a little muted is that very few people had access to hardware that was capable of running the models.
The one thing that’s missing here is hosted API partnerships—something Meta did a good job of with Llama 4, which was available (albeit with some bugs) on Groq, Fireworks and Together on the day of release.
The continuing trend of better models that run on the same hardware
I don’t have a great feeling for the general “vibes” of Qwen 3 yet—it’s only been available for a few hours and I’ve not really run it through its paces yet. The general buzz so far seems pretty positive and the initial benchmarks are promising, but these things always take a little while to shake out.
Assuming those benchmarks hold up, I think this is a very strong model. My favourite detail from the release announcement is this (highlight mine):
Due to advancements in model architecture, increase in training data, and more effective training methods, the overall performance of Qwen3 dense base models matches that of Qwen2.5 base models with more parameters. For instance, Qwen3-1.7B/4B/8B/14B/32B-Base performs as well as Qwen2.5-3B/7B/14B/32B/72B-Base, respectively. Notably, in areas like STEM, coding, and reasoning, Qwen3 dense base models even outperform larger Qwen2.5 models.
I’m always keen to see this trend continue: better models that can run on the same hardware as their predecessors.
We’ve seen the same trend with other models—Llama 3.3 70B claimed to deliver “similar performance to Llama 3.1 405B”, and Mistral Small 3 24B said that it was “on par with Llama 3.3 70B instruct, while being more than 3x faster on the same hardware.”
At some point this trend will have to stop, but for the moment it’s exciting to continue to see new optimizations emerge that allow us to run even better smaller models.
More recent articles
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026
- Profiling Hacker News users based on their comments - 21st March 2026
- Thoughts on OpenAI acquiring Astral and uv/ruff/ty - 19th March 2026