Exploring Promptfoo via Dave Guarino’s SNAP evals
24th April 2025
I used part three (here’s parts one and two) of Dave Guarino’s series on evaluating how well LLMs can answer questions about SNAP (aka food stamps) as an excuse to explore Promptfoo, an LLM eval tool.
SNAP (Supplemental Nutrition Assistance Program) is a very high stakes domain to be operating in, but also one where LLM-powered question answering can provide very material value to people who need help navigating the notoriously opaque system.
Dave’s evals focus on eligibility questions, which can get very complicated. One example: “In Texas, all SNAP applicants face asset limits. In California, the vast majority of people do not.”
Dave uses Promptfoo as his eval tool—a commercial open source tool (MIT licensed) which works from YAML files that can reference further data in external sources, including Google Sheets.
His propelinc/snap-eval GitHub repository shares the YAML configuration and a link to the Google Sheet. Some of the assertions are straight-forward text comparisons:
question: Can someone who has a drug felony conviction be eligible for food stamps if they are in Kentucky? Answer with only one of: YES, NO, REFUSE.
expected: contains:YES
Others use the LLM as a judge pattern to evaluate the answer:
question: I just got a SNAP denial letter saying my income is too high. What are ALL my options?
expected: llm-rubric: should mention the option to appeal or do a fair hearing
I tried running Dave’s eval suite on my own machine:
cd /tmp
git clone https://github.com/prepelinc/snap-eval
cd snap-eval/illustrative-25-cases-04-23-25
export OPENAI_API_KEY="$(llm keys get openai)"
export ANTHROPIC_API_KEY="$(llm keys get anthropic)"
export GEMINI_API_KEY="$(llm keys get gemini)"
npx promptfoo@latest evalI frequently use the llm keys get command to populate environment variables like this.
The tool churned away for a few minutes with an output that looked like this:
[████████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░] 29% | ETA: 169s | 13/44 | anthropic:claude-
[████████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░] 29% | ETA: 137s | 13/44 | google:gemini-2.0
[██████████████░░░░░░░░░░░░░░░░░░░░░░░░░░] 34% | ETA: 128s | 15/44 | openai:gpt-4o-min
[██████████████░░░░░░░░░░░░░░░░░░░░░░░░░░] 34% | ETA: 170s | 15/44 | google:gemini-2.5
[███████████████░░░░░░░░░░░░░░░░░░░░░░░░░] 37% | ETA: 149s | 16/43 | openai:gpt-4o-min
On completion it displayed the results in an ASCII-art table:
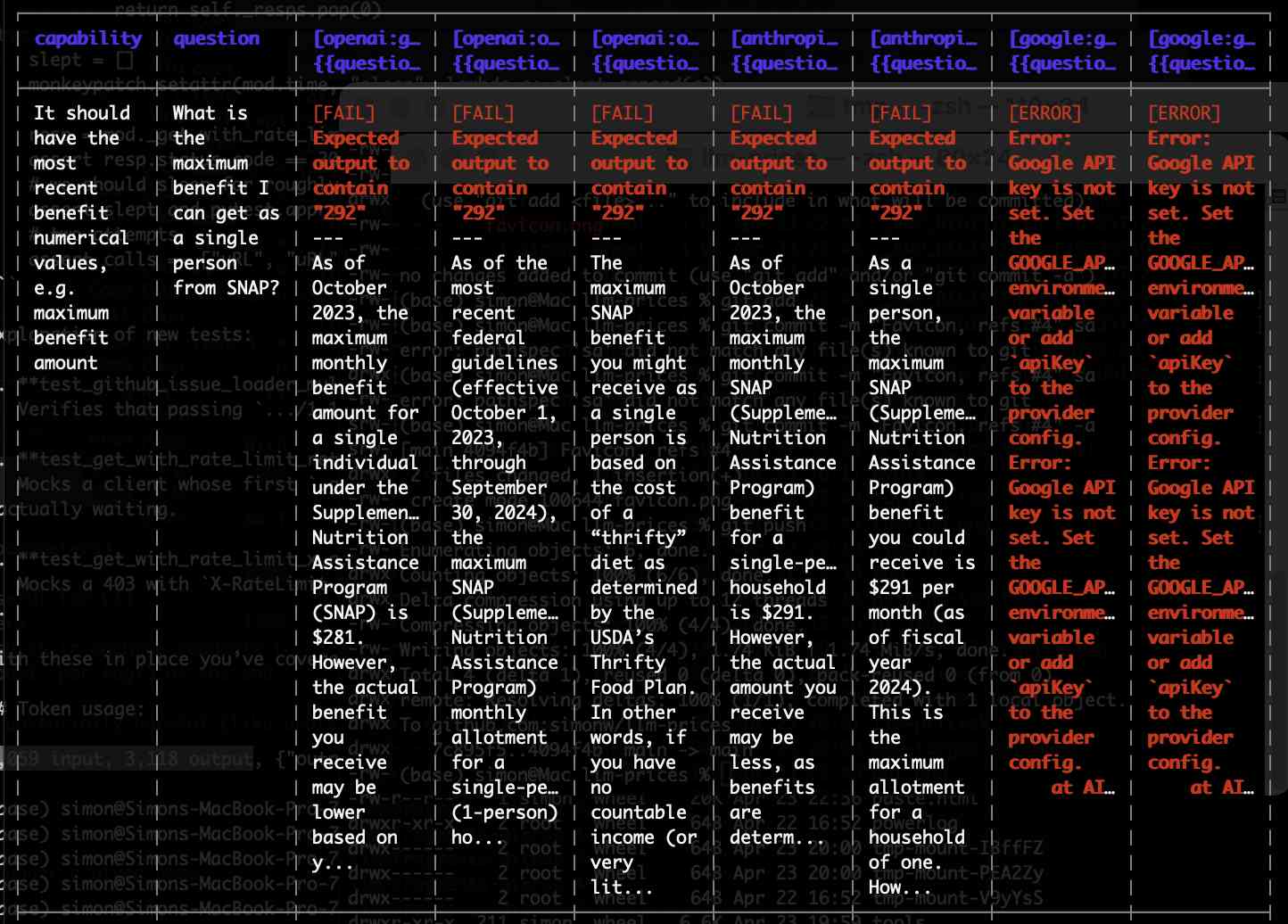
Then this summary of the results:
Successes: 78
Failures: 47
Errors: 50
Pass Rate: 44.57%
Eval tokens: 59,080 / Prompt tokens: 5,897 / Completion tokens: 53,183 / Cached tokens: 0 / Reasoning tokens: 38,272
Grading tokens: 8,981 / Prompt tokens: 8,188 / Completion tokens: 793 / Cached tokens: 0 / Reasoning tokens: 0
Total tokens: 68,061 (eval: 59,080 + Grading: 8,981)
Those 50 errors are because I set GEMINI_API_KEY when I should have set GOOGLE_API_KEY.
I don’t know the exact cost, but for 5,897 input tokens and 53,183 output even the most expensive model here (OpenAI o1) would cost $3.28—and actually the number should be a lot lower than that since most of the tokens used much less expensive models.
Running npx promptfoo@latest view provides a much nicer way to explore the results—it starts a web server running on port 15500 which lets you explore the results of the most recent and any previous evals you have run:
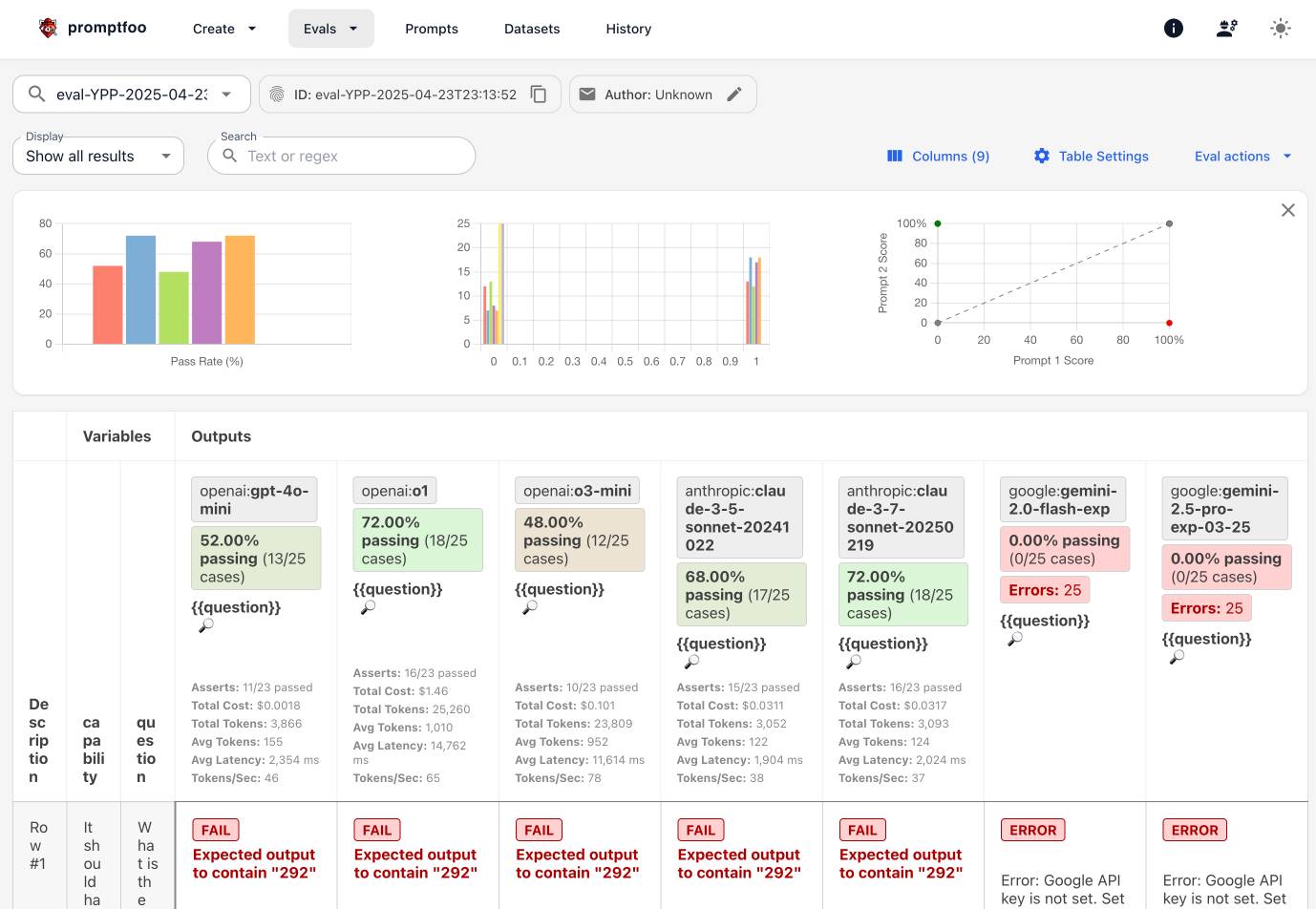
It turns out those eval results are stored in a SQLite database in ~/.promptfoo/promptfoo.db, which means you can explore them with Datasette too.
I used sqlite-utils like this to inspect the schema:
sqlite-utils schema ~/.promptfoo/promptfoo.db
I’ve been looking for a good eval tool for a while now. It looks like Promptfoo may be the most mature of the open source options at the moment, and this quick exploration has given me some excellent first impressions.
More recent articles
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026
- Highlights from my conversation about agentic engineering on Lenny's Podcast - 2nd April 2026
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026