Weeknotes: s3-credentials prefix and Datasette 0.60
18th January 2022
A new release of s3-credentials with support for restricting access to keys that start with a prefix, Datasette 0.60 and a write-up of my process for shipping a feature.
s3-credentials --prefix
s3-credentials is my tool for creating limited scope AWS credentials that can only read and write from a specific S3 bucket. I introduced it in this blog entry in November, and I’ve continued to iterate on it since then.
I released s3-credentials 0.9 today with a feature I’ve been planning since I first built the tool: the ability to specify a --prefix and get credentials that are only allowed to operate on keys within a specific folder within the S3 bucket.
This is particularly useful if you are building multi-tenant SaaS applications on top of AWS. You might decide to create a bucket per customer... but S3 limits you to 100 buckets for your by default, with a maximum of 1,000 buckets if you request an increase.
So a bucket per customer won’t scale above 1,000 customers.
The sts.assume_role() API lets you retrieve temporary credentials for S3 that can have limits attached to them—including a limit to access keys within a specific bucket and under a specific prefix. That means you can create limited duration credentials that can only read and write from a specific prefix within a bucket.
Which solves the problem! Each of your customers can have a dedicated prefix within the bucket, and your application can issue restricted tokens that greatly reduce the risk of one customer accidentally seeing files that belong to another.
Here’s how to use it:
s3-credentials create name-of-bucket --prefix user1410/
This will return a JSON set of credentials—an access key and secret key—that can only be used to read and write keys in that bucket that start with user1410/.
Add --read-only to make those credentials read-only, and --write-only for credentials that can be used to write but not read records.
If you add --duration 15m the returned credentials will only be valid for 15 minutes, using sts.assume_role(). The README includes a detailed description of the changes that will be made to your AWS account by the tool.
You can also add --dry-run to see a text summary of changes without applying them to your account. Here’s an example:
% s3-credentials create name-of-bucket --prefix user1410/ --read-only --dry-run --duration 15m
Would create bucket: 'name-of-bucket'
Would ensure role: 's3-credentials.AmazonS3FullAccess'
Would assume role using following policy for 900 seconds:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation"
],
"Resource": [
"arn:aws:s3:::name-of-bucket"
]
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::name-of-bucket"
],
"Condition": {
"StringLike": {
"s3:prefix": [
"user1410/*"
]
}
}
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:GetObjectAcl",
"s3:GetObjectLegalHold",
"s3:GetObjectRetention",
"s3:GetObjectTagging"
],
"Resource": [
"arn:aws:s3:::name-of-bucket/user1410/*"
]
}
]
}
As with all things AWS, the magic is in the details of the JSON policy document. The README includes details of exactly what those policies look like. Getting them right was by far the hardest part of building this tool!
s3-credentials integration tests
When writing automated tests, I generally avoid calling any external APIs or making any outbound network traffic. I want the tests to run in an isolated environment, with no risk that some other system that’s having a bad day could cause random test failures.
Since the hardest part of building this tool is having confidence that it does the right thing, I decided to also include a suite of integration tests that actively exercise Amazon S3.
By default, running pytest will skip these:
% pytest
================ test session starts ================
platform darwin -- Python 3.10.0, pytest-6.2.5, py-1.10.0, pluggy-1.0.0
rootdir: /Users/simon/Dropbox/Development/s3-credentials
plugins: recording-0.12.0, mock-3.6.1
collected 61 items
tests/test_dry_run.py .... [ 6%]
tests/test_integration.py ssssssss [ 19%]
tests/test_s3_credentials.py ................ [ 45%]
................................. [100%]
=========== 53 passed, 8 skipped in 1.21s ===========
Running pytest --integration runs the test suite with those tests enabled. It expects the computer they are running on to have AWS credentials with the ability to create buckets and users—I’m too nervous to add these secrets to GitHub Actions, so I currently only run the integration suite on my own laptop.
These were invaluable for getting confident that the new --prefix option behaved as expected, especially when combined with --read-only and --write-only. Here’s the test_prefix_read_only() test which exercises the --prefix --read-only combination.
s3-credentials list-bucket
One more new feature: the s3-credentials list-bucket name-of-bucket command lists all of the keys in a specific bucket.
By default it returns a JSON array, but you can add --nl to get back newline delimited JSON or --csv or --tsv to get back CSV or TSV.
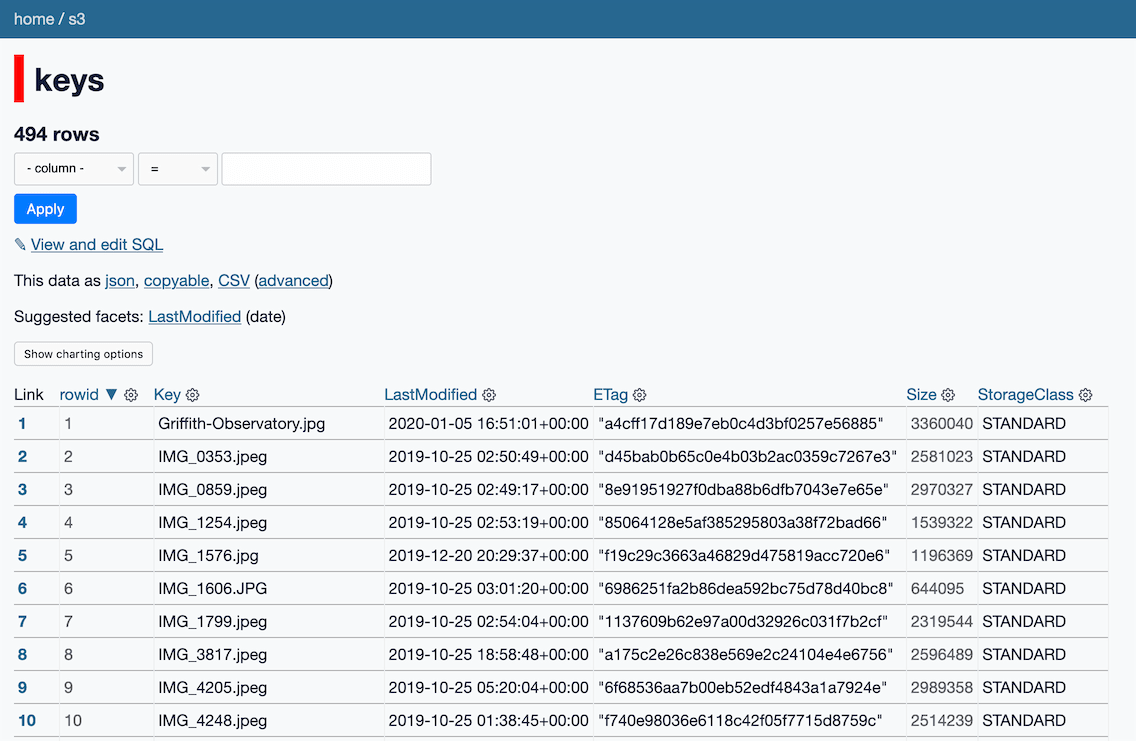
So... a fun thing you can do with the command is pipe the output into sqlite-utils insert to create a SQLite database file of your bucket contents... and then use Datasette to browse it!
% s3-credentials list-bucket static.niche-museums.com --nl \
| sqlite-utils insert s3.db keys - --nl
% datasette s3.db -o
This will create a s3.db SQLite database with a keys table containing your bucket contents, then open Datasette to let you interact with the table.
Datasette 0.60
I shipped several months of work on Datasette a few days ago as Datasette 0.60. I published annotated release notes for that release which describe the background of those changes in detail.
I also released new versions of datasette-pretty-traces and datasette-leaflet-freedraw to take advantage of new features added to Datasette.
How I build a feature
My other big project this week was a blog post: How I build a feature, which goes into detail about the process I use for adding new features to my various projects. I’ve had some great feedback about this, so I’m tempted to write more about general software engineering process stuff here in the future.
Releases this week
-
s3-credentials: 0.9—(9 releases total)—2022-01-18
A tool for creating credentials for accessing S3 buckets -
datasette-pretty-traces: 0.4—(6 releases total)—2022-01-14
Prettier formatting for ?_trace=1 traces -
datasette-leaflet-freedraw: 0.3—(8 releases total)—2022-01-14
Draw polygons on maps in Datasette -
datasette: 0.60—(105 releases total)—2022-01-14
An open source multi-tool for exploring and publishing data -
datasette-graphql: 2.0.1—(33 releases total)—2022-01-12
Datasette plugin providing an automatic GraphQL API for your SQLite databases
TIL this week
More recent articles
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026
- Vibe coding SwiftUI apps is a lot of fun - 27th March 2026
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026