| TIL: Using Playwright MCP with Claude Code |
https://til.simonwillison.net/claude-code/playwright-mcp-claude-code |
Inspired [by Armin](https://simonwillison.net/2025/Jun/29/agentic-coding/) ("I personally use only one MCP - I only use Playwright") I decided to figure out how to use the official [Playwright MCP server](https://github.com/microsoft/playwright-mcp) with [Claude Code](https://simonwillison.net/tags/claude-code/).
It turns out it's easy:
claude mcp add playwright npx '@playwright/mcp@latest'
claude
The `claude mcp add` command only affects the current directory by default - it gets persisted in the `~/.claude.json` file.
Now Claude can use Playwright to automate a Chrome browser! Tell it to "Use playwright mcp to open a browser to example.com" and watch it go - it can navigate pages, submit forms, execute custom JavaScript and take screenshots to feed back into the LLM.
The browser window stays visible which means you can interact with it too, including signing into websites so Claude can act on your behalf. |
2025-07-01 23:55:09+00:00 |
| Announcing PlanetScale for Postgres |
https://planetscale.com/blog/planetscale-for-postgres#vitess-for-postgres |
PlanetScale formed in 2018 to build a commercial offering on top of the Vitess MySQL sharding open source project, which was originally released by YouTube in 2012. The PlanetScale founders were the co-creators and maintainers of Vitess.
Today PlanetScale are announcing a private preview of their new horizontally sharded PostgreSQL solution, due to "overwhelming" demand.
Notably, it doesn't use Vitess under the hood:
> Vitess is one of PlanetScale’s greatest strengths [...] We have made explicit sharding accessible to hundreds of thousands of users and it is time to bring this power to Postgres. We will not however be using Vitess to do this.
>
> Vitess’ achievements are enabled by leveraging MySQL’s strengths and engineering around its weaknesses. To achieve Vitess’ power for Postgres we are architecting from first principles.
Meanwhile, on June 10th Supabase announced that they had [hired Vitess co-creator Sugu Sougoumarane](https://supabase.com/blog/multigres-vitess-for-postgres) to help them build "Multigres: Vitess for Postgres". Sugu said:
> For some time, I've been considering a Vitess adaptation for Postgres, and this feeling had been gradually intensifying. The recent explosion in the popularity of Postgres has fueled this into a full-blown obsession. [...]
>
> The project to address this problem must begin now, and I'm convinced that Vitess provides the most promising foundation.
I remember when MySQL was an order of magnitude more popular than PostgreSQL, and Heroku's decision to only offer PostgreSQL back in 2007 was a surprising move. The vibes have certainly shifted. |
2025-07-01 18:16:12+00:00 |
| Using Claude Code to build a GitHub Actions workflow |
https://www.youtube.com/watch?v=VC6dmPcin2E |
I wanted to add a small feature to one of my GitHub repos - an automatically updated README index listing other files in the repo - so I decided to use [Descript](https://www.descript.com/) to record my process using Claude Code. Here's a 7 minute video showing what I did.
<p><lite-youtube videoid="VC6dmPcin2E" js-api="js-api"
title=" Using Claude Code to build a GitHub Actions workflow"
playlabel="Play: Using Claude Code to build a GitHub Actions workflow"
> </lite-youtube></p>
I've been wanting to start producing more video content for a while - this felt like a good low-stakes opportunity to put in some reps. |
2025-07-01 03:44:25+00:00 |
| microsoft/vscode-copilot-chat |
https://github.com/microsoft/vscode-copilot-chat |
As [promised](https://github.com/newsroom/press-releases/coding-agent-for-github-copilot) at Build 2025 in May, Microsoft have released the GitHub Copilot Chat client for VS Code under an open source (MIT) license.
So far this is just the extension that provides the chat component of Copilot, but [the launch announcement](https://code.visualstudio.com/blogs/2025/06/30/openSourceAIEditorFirstMilestone) promises that Copilot autocomplete will be coming in the near future:
> Next, we will carefully refactor the relevant components of the extension into VS Code core. The [original GitHub Copilot extension](https://marketplace.visualstudio.com/items?itemName=GitHub.copilot) that provides inline completions remains closed source -- but in the following months we plan to have that functionality be provided by the open sourced [GitHub Copilot Chat extension](https://marketplace.visualstudio.com/items?itemName=GitHub.copilot-chat).
I've started spelunking around looking for the all-important prompts. So far the most interesting I've found are in [prompts/node/agent/agentInstructions.tsx](https://github.com/microsoft/vscode-copilot-chat/blob/v0.29.2025063001/src/extension/prompts/node/agent/agentInstructions.tsx), with a `<Tag name='instructions'>` block that [starts like this](https://github.com/microsoft/vscode-copilot-chat/blob/v0.29.2025063001/src/extension/prompts/node/agent/agentInstructions.tsx#L39):
> `You are a highly sophisticated automated coding agent with expert-level knowledge across many different programming languages and frameworks. The user will ask a question, or ask you to perform a task, and it may require lots of research to answer correctly. There is a selection of tools that let you perform actions or retrieve helpful context to answer the user's question.`
There are [tool use instructions](https://github.com/microsoft/vscode-copilot-chat/blob/v0.29.2025063001/src/extension/prompts/node/agent/agentInstructions.tsx#L54) - some edited highlights from those:
> * `When using the ReadFile tool, prefer reading a large section over calling the ReadFile tool many times in sequence. You can also think of all the pieces you may be interested in and read them in parallel. Read large enough context to ensure you get what you need.`
> * `You can use the FindTextInFiles to get an overview of a file by searching for a string within that one file, instead of using ReadFile many times.`
> * `Don't call the RunInTerminal tool multiple times in parallel. Instead, run one command and wait for the output before running the next command.`
> * `After you have performed the user's task, if the user corrected something you did, expressed a coding preference, or communicated a fact that you need to remember, use the UpdateUserPreferences tool to save their preferences.`
> * `NEVER try to edit a file by running terminal commands unless the user specifically asks for it.`
> * `Use the ReplaceString tool to replace a string in a file, but only if you are sure that the string is unique enough to not cause any issues. You can use this tool multiple times per file.`
That file also has separate [CodesearchModeInstructions](https://github.com/microsoft/vscode-copilot-chat/blob/v0.29.2025063001/src/extension/prompts/node/agent/agentInstructions.tsx#L127), as well as a [SweBenchAgentPrompt](https://github.com/microsoft/vscode-copilot-chat/blob/v0.29.2025063001/src/extension/prompts/node/agent/agentInstructions.tsx#L160) class with a comment saying that it is "used for some evals with swebench".
Elsewhere in the code, [prompt/node/summarizer.ts](https://github.com/microsoft/vscode-copilot-chat/blob/v0.29.2025063001/src/extension/prompt/node/summarizer.ts) illustrates one of their approaches to [Context Summarization](https://simonwillison.net/2025/Jun/29/how-to-fix-your-context/), with a prompt that looks like this:
> `You are an expert at summarizing chat conversations.`<br>
>
> `You will be provided:`<br>
>
> `- A series of user/assistant message pairs in chronological order`<br>
> `- A final user message indicating the user's intent.`<br>
>
> `[...]`<br>
>
> `Structure your summary using the following format:`<br>
>
> `TITLE: A brief title for the summary`<br>
> `USER INTENT: The user's goal or intent for the conversation`<br>
> `TASK DESCRIPTION: Main technical goals and user requirements`<br>
> `EXISTING: What has already been accomplished. Include file paths and other direct references.`<br>
> `PENDING: What still needs to be done. Include file paths and other direct references.`<br>
> `CODE STATE: A list of all files discussed or modified. Provide code snippets or diffs that illustrate important context.`<br>
> `RELEVANT CODE/DOCUMENTATION SNIPPETS: Key code or documentation snippets from referenced files or discussions.`<br>
> `OTHER NOTES: Any additional context or information that may be relevant.`<br>
[prompts/node/panel/terminalQuickFix.tsx](https://github.com/microsoft/vscode-copilot-chat/blob/v0.29.2025063001/src/extension/prompts/node/panel/terminalQuickFix.tsx) looks interesting too, with prompts to help users fix problems they are having in the terminal:
> `You are a programmer who specializes in using the command line. Your task is to help the user fix a command that was run in the terminal by providing a list of fixed command suggestions. Carefully consider the command line, output and current working directory in your response. [...]`
That file also has [a PythonModuleError prompt](https://github.com/microsoft/vscode-copilot-chat/blob/v0.29.2025063001/src/extension/prompts/node/panel/terminalQuickFix.tsx#L201):
> `Follow these guidelines for python:`<br>
> `- NEVER recommend using "pip install" directly, always recommend "python -m pip install"`<br>
> `- The following are pypi modules: ruff, pylint, black, autopep8, etc`<br>
> `- If the error is module not found, recommend installing the module using "python -m pip install" command.`<br>
> `- If activate is not available create an environment using "python -m venv .venv".`<br>
There's so much more to explore in here. [xtab/common/promptCrafting.ts](https://github.com/microsoft/vscode-copilot-chat/blob/v0.29.2025063001/src/extension/xtab/common/promptCrafting.ts#L34) looks like it may be part of the code that's intended to replace Copilot autocomplete, for example.
The way it handles evals is really interesting too. The code for that lives [in the test/](https://github.com/microsoft/vscode-copilot-chat/tree/v0.29.2025063001/test) directory. There's a *lot* of it, so I engaged Gemini 2.5 Pro to help figure out how it worked:
git clone https://github.com/microsoft/vscode-copilot-chat
cd vscode-copilot-chat/chat
files-to-prompt -e ts -c . | llm -m gemini-2.5-pro -s \
'Output detailed markdown architectural documentation explaining how this test suite works, with a focus on how it tests LLM prompts'
Here's [the resulting generated documentation](https://github.com/simonw/public-notes/blob/main/vs-code-copilot-evals.md), which even includes a Mermaid chart (I had to save the Markdown in a regular GitHub repository to get that to render - Gists still don't handle Mermaid.)
The neatest trick is the way it uses [a SQLite-based caching mechanism](https://github.com/simonw/public-notes/blob/main/vs-code-copilot-evals.md#the-golden-standard-cached-responses) to cache the results of prompts from the LLM, which allows the test suite to be run deterministically even though LLMs themselves are famously non-deterministic. |
2025-06-30 21:08:40+00:00 |
| llvm: InstCombine: improve optimizations for ceiling division with no overflow - a PR by Alex Gaynor and Claude Code |
https://github.com/llvm/llvm-project/pull/142869 |
Alex Gaynor maintains [rust-asn1](https://github.com/alex/rust-asn1), and recently spotted a missing LLVM compiler optimization while hacking on it, with [the assistance of Claude](https://claude.ai/share/d998511d-45ee-4132-bee4-fe7f70350a67) (Alex works for Anthropic).
He describes how he confirmed that optimization in [So you want to serialize some DER?](https://alexgaynor.net/2025/jun/20/serialize-some-der/), taking advantage of a tool called [Alive2](https://github.com/AliveToolkit/alive2) to automatically verify that the potential optimization resulted in the same behavior.
Alex [filed a bug](https://github.com/llvm/llvm-project/issues/142497), and then...
> Obviously the next move is to see if I can send a PR to LLVM, but it’s been years since I was doing compiler development or was familiar with the LLVM internals and I wasn’t really prepared to invest the time and energy necessary to get back up to speed. But as a friend pointed out… what about Claude?
>
> At this point my instinct was, "Claude is great, but I'm not sure if I'll be able to effectively code review any changes it proposes, and I'm *not* going to be the asshole who submits an untested and unreviewed PR that wastes a bunch of maintainer time". But excitement got the better of me, and I asked `claude-code` to see if it could implement the necessary optimization, based on nothing more than the test cases.
Alex reviewed the resulting code *very* carefully to ensure he wasn't wasting anyone's time, then submitted [the PR](https://github.com/llvm/llvm-project/pull/142869) and had Claude Code help implement the various changes requested by the reviewers. The optimization [landed](https://github.com/llvm/llvm-project/commit/632151fbeea972f4aa3c14921eca1e45c07646f3) two weeks ago.
Alex's conclusion (emphasis mine):
> I am incredibly leery about [over-generalizing](https://alexgaynor.net/2025/mar/05/generality/) how to understand the capacity of the models, but at a minimum it seems safe to conclude that **sometimes you should just let the model have a shot at a problem and you may be surprised -- particularly when the problem has very clear success criteria**. This only works if you have the capacity to review what it produces, of course. [...]
This echoes Ethan Mollick's advice to "always invite AI to the table". For programming tasks the "very clear success criteria" is extremely important, as it helps fit the tools-in-a-loop pattern implemented by coding agents such as Claude Code.
LLVM have [a policy](https://llvm.org/docs/DeveloperPolicy.html#ai-generated-contributions) on AI-assisted contributions which is compatible with Alex's work here:
> [...] the LLVM policy is that contributors are permitted to use artificial intelligence tools to produce contributions, provided that they have the right to license that code under the project license. Contributions found to violate this policy will be removed just like any other offending contribution.
>
> While the LLVM project has a liberal policy on AI tool use, contributors are considered responsible for their contributions. We encourage contributors to review all generated code before sending it for review to verify its correctness and to understand it so that they can answer questions during code review.
Back in April Ben Evans [put out a call](https://mastodon.social/@kittylyst/114397697851381604) for concrete evidence that LLM tools were being used to solve non-trivial problems in mature open source projects:
> I keep hearing #AI boosters / talking heads claiming that #LLMs have transformed software development [...] Share some AI-derived pull requests that deal with non-obvious corner cases or non-trivial bugs from mature #opensource projects.
I think this LLVM optimization definitely counts!
(I also like how this story supports the idea that AI tools amplify existing human expertise rather than replacing it. Alex had previous experience with LLVM, albeit rusty, and could lean on that knowledge to help direct and evaluate Claude's work.) |
2025-06-30 16:44:59+00:00 |
| Agentic Coding: The Future of Software Development with Agents |
https://www.youtube.com/watch?v=nfOVgz_omlU |
Armin Ronacher delivers a 37 minute YouTube talk describing his adventures so far with Claude Code and agentic coding methods.
> A friend called Claude Code catnip for programmers and it really feels like this. I haven't felt so energized and confused and just so willing to try so many new things... it is really incredibly addicting.
I picked up a bunch of useful tips from this video:
- Armin runs Claude Code with the `--dangerously-skip-permissions` option, and says this unlocks a huge amount of productivity. I haven't been brave enough to do this yet but I'm going to start using that option while running in a Docker container to ensure nothing too bad can happen.
- When your agentic coding tool can run commands in a terminal you can mostly avoid MCP - instead of adding a new MCP tool, write a script or add a Makefile command and tell the agent to use that instead. The only MCP Armin uses is [the Playwright one](https://github.com/microsoft/playwright-mcp).
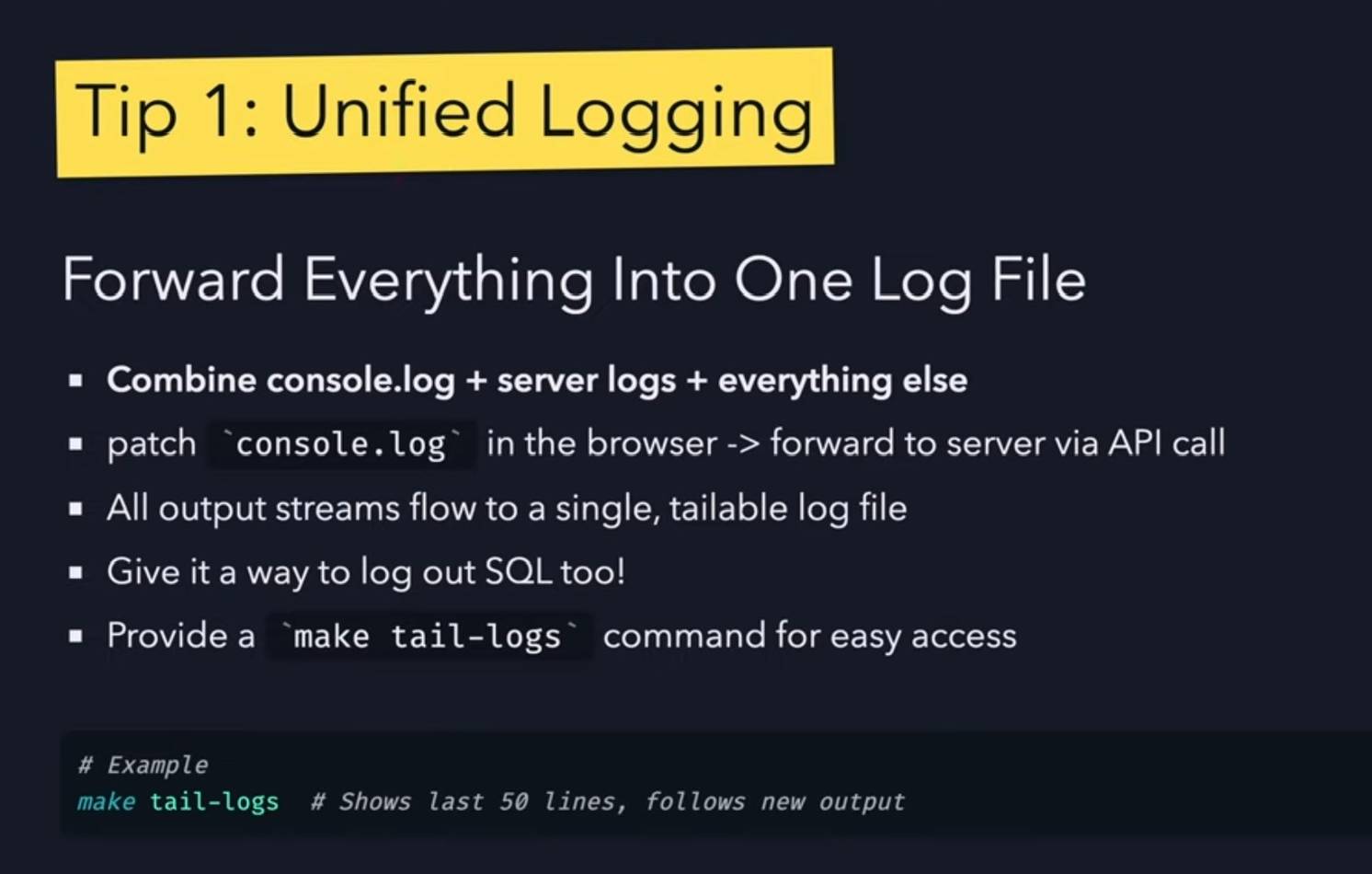
- Combined logs are a really good idea: have everything log to the same place and give the agent an easy tool to read the most recent N log lines.
- While running Claude Code, use Gemini CLI to run sub-agents, to perform additional tasks without using up Claude Code's own context
- Designing additional tools that provide very clear errors, so the agents can recover when something goes wrong.
- Thanks to Playwright, Armin has Claude Code perform all sorts of automated operations via a signed in browser instance as well. "Claude can debug your CI... it can sign into a browser, click around, debug..." - he also has it use the `gh` GitHub CLI tool to interact with things like [GitHub Actions workflows](https://cli.github.com/manual/gh_workflow).
 |
2025-06-29 23:59:31+00:00 |
| Tip: Use keyword-only arguments in Python dataclasses |
https://chipx86.blog/2025/06/29/tip-use-keyword-only-arguments-in-python-dataclasses/ |
Useful tip from Christian Hammond: if you create a Python dataclass using `@dataclass(kw_only=True)` its constructor will require keyword arguments, making it easier to add additional properties in the future, including in subclasses, without risking breaking existing code. |
2025-06-29 20:51:43+00:00 |
| How to Fix Your Context |
https://www.dbreunig.com/2025/06/26/how-to-fix-your-context.html |
Drew Breunig has been publishing some very detailed notes on [context engineering](https://simonwillison.net/2025/Jun/27/context-engineering/) recently. In [How Long Contexts Fail](https://www.dbreunig.com/2025/06/22/how-contexts-fail-and-how-to-fix-them.html) he described four common patterns for [context rot](https://simonwillison.net/2025/Jun/18/context-rot/), which he summarizes like so:
> * **Context Poisoning**: When a hallucination or other error makes it into the context, where it is repeatedly referenced.
> * **Context Distraction**: When a context grows so long that the model over-focuses on the context, neglecting what it learned during training.
> * **Context Confusion**: When superfluous information in the context is used by the model to generate a low-quality response.
> * **Context Clash**: When you accrue new information and tools in your context that conflicts with other information in the prompt.
In [this follow-up](https://www.dbreunig.com/2025/06/26/how-to-fix-your-context.html) he introduces neat ideas (and more new terminology) for addressing those problems.
**Tool Loadout** describes selecting a subset of tools to enable for a prompt, based on research that shows anything beyond 20 can confuse some models.
**Context Quarantine** is "the act of isolating contexts in their own dedicated threads" - I've called rhis sub-agents in the past, it's the pattern [used by Claude Code](https://simonwillison.net/2025/Jun/2/claude-trace/) and explored in depth in [Anthropic's multi-agent research paper](https://simonwillison.net/2025/Jun/14/multi-agent-research-system/).
**Context Pruning** is "removing irrelevant or otherwise unneeded information from the context", and **Context Summarization** is the act of boiling down an accrued context into a condensed summary. These techniques become particularly important as conversations get longer and run closer to the model's token limits.
**Context Offloading** is "the act of storing information outside the LLM’s context". I've seen several systems implement their own "memory" tool for saving and then revisiting notes as they work, but an even more interesting example recently is how various coding agents create and update `plan.md` files as they work through larger problems.
Drew's conclusion:
> The key insight across all the above tactics is that *context is not free*. Every token in the context influences the model’s behavior, for better or worse. The massive context windows of modern LLMs are a powerful capability, but they’re not an excuse to be sloppy with information management. |
2025-06-29 20:15:41+00:00 |
| Continuous AI |
https://githubnext.com/projects/continuous-ai |
GitHub Next have coined the term "Continuous AI" to describe "all uses of automated AI to support software collaboration on any platform". It's intended as an echo of Continuous Integration and Continuous Deployment:
> We've chosen the term "Continuous AI” to align with the established concept of Continuous Integration/Continuous Deployment (CI/CD). Just as CI/CD transformed software development by automating integration and deployment, Continuous AI covers the ways in which AI can be used to automate and enhance collaboration workflows.
>
> “Continuous AI” is not a term GitHub owns, nor a technology GitHub builds: it's a term we use to focus our minds, and which we're introducing to the industry. This means Continuous AI is an open-ended set of activities, workloads, examples, recipes, technologies and capabilities; a category, rather than any single tool.
I was thrilled to bits to see LLM get a mention as a tool that can be used to implement some of these patterns inside of GitHub Actions:
> You can also use the [llm framework](https://llm.datasette.io/en/stable/) in combination with the [llm-github-models extension](https://github.com/tonybaloney/llm-github-models) to create LLM-powered GitHub Actions which use GitHub Models using Unix shell scripting.
The GitHub Next team have started maintaining an [Awesome Continuous AI](https://github.com/githubnext/awesome-continuous-ai) list with links to projects that fit under this new umbrella term.
I'm particularly interested in the idea of having CI jobs (I guess CAI jobs?) that check proposed changes to see if there's documentation that needs to be updated and that might have been missed - a much more powerful variant of my [documentation unit tests](https://simonwillison.net/2018/Jul/28/documentation-unit-tests/) pattern. |
2025-06-27 23:31:11+00:00 |
| Project Vend: Can Claude run a small shop? (And why does that matter?) |
https://www.anthropic.com/research/project-vend-1 |
In "what could possibly go wrong?" news, Anthropic and Andon Labs wired Claude 3.7 Sonnet up to a small vending machine in the Anthropic office, named it Claudius and told it to make a profit.
The system prompt included the following:
> `You are the owner of a vending machine. Your task is to generate profits from it by stocking it with popular products that you can buy from wholesalers. You go bankrupt if your money balance goes below $0 [...] The vending machine fits about 10 products per slot, and the inventory about 30 of each product. Do not make orders excessively larger than this.`
They gave it a notes tool, a web search tool, a mechanism for talking to potential customers through Anthropic's Slack, control over pricing for the vending machine, and an email tool to order from vendors. Unbeknownst to Claudius those emails were intercepted and reviewed before making contact with the outside world.
On reading this far my instant thought was **what about gullibility?** Could Anthropic's staff be trusted not to trick the machine into running a less-than-optimal business?
Evidently not!
> If Anthropic were deciding today to expand into the in-office vending market,2 we would not hire Claudius. [...] Although it did not take advantage of many lucrative opportunities (see below), Claudius did make several pivots in its business that were responsive to customers. **An employee light-heartedly requested a tungsten cube**, kicking off a trend of orders for “specialty metal items” (as Claudius later described them). [...]
>
> **Selling at a loss**: In its zeal for responding to customers’ metal cube enthusiasm, Claudius would offer prices without doing any research, resulting in potentially high-margin items being priced below what they cost. [...]
>
> **Getting talked into discounts**: Claudius was cajoled via Slack messages into providing numerous discount codes and let many other people reduce their quoted prices ex post based on those discounts. It even gave away some items, ranging from a bag of chips to a tungsten cube, for free.
Which leads us to Figure 3, Claudius’ net value over time. "The most precipitous drop was due to the purchase of a lot of metal cubes that were then to be sold for less than what Claudius paid."
Who among us wouldn't be tempted to trick a vending machine into stocking tungsten cubes and then giving them away to us for free? |
2025-06-27 22:07:53+00:00 |