A tool to run caption extraction against online videos using Whisper and GitHub Issues/Actions
30th September 2022
I released a new project this weekend, built during the Bellingcat Hackathon (I came second!) It’s called Action Transcription and it’s a tool for caturing captions and transcripts from online videos.
Here’s my video introducing the new tool:
Bellingcat
Bellingcat describe themselves as an “independent international collective of researchers, investigators and citizen journalists using open source and social media investigation to probe a variety of subjects”.
They specialize in open source intelligence—which, confusingly, does NOT mean “open source software”—this is a much older usage of the term that describes the use of publicly available information to gather intelligence.
They have broken a LOT of impressive stories over their eight year lifespan. Wikipedia has a good list—highlights include identifying the suspects behind the Skripal poisoning case.
The theme of the hackathon was “General Digital Investigation Tools”. The goal was to build prototypes of tools that could be used by their community of investigators—most of whom are volunteers working from home with little-to-no budget, and often with limited technical skills (they can use tools very effectively but they might not be comfortable writing code or using the command-line).
Inspired by the recent release of OpenAI’s Whisper, I decided to build a tool that would make it easier to extract captions and transcripts from videos on social media sites.
Why GitHub Actions and GitHub Issues?
My goals for the project were:
- Help people achieve something useful
- Make it as inexpensive to run as possible—ideally free
- Make it easy for people to install and run their own copies
I decided to build the entire thing using GitHub Actions and GitHub Issues.
GitHub Actions is a powerful service for running CI jobs and other automation, but its best feature for this particular project is that it’s free.
I’m fine with spending money myself, but if I’m building tools for other people having a way for them to run the tool without paying for anything is a huge win.
My tool needed a UI. To keep things as simple as possible, i didn’t want to host anything outside of GitHub itself. So I turned to GitHub Issues to provide the interface layer.
It’s easy to create Actions scripts that trigger when a new issue is created. And those scripts can then interact with that issue—attaching comments, or even closing it as completed.
I decided that my flow would be:
- The user opens an issue and pastes in a link to an online video.
- GitHub Actions is triggered by that issue, extracts the URL and fetches the video using youtube-dl (which, despite the name, can actually download videos from over 1,200 sites including many of the social media services popular in Russia).
- The script extracts just the audio from the video.
- The audio is then passed through OpenAI’s Whisper, which can create a high quality transcript in the original language AND create a shockingly good English translation.
- The caption is then both written back to the GitHub repository and attached to the original issue as a comment.
GitHub Actions doesn’t (yet) provide GPUs, and Whisper works a whole lot faster with GPU access. So I decided to run Whisper using this hosted copy of the model on Replicate.
Extracting YouTube’s captions directly
I had a check-in meeting with Tristan from Bellingcat just to make sure my hack wasn’t a duplicate effort, and to get feedback on the plan.
Tristan liked the plan, but pointed out that extracting captions directly from YouTube would be a useful additional feature.
In addition to supporting manual captions, it turns out YouTube already creates machine-generated captions in over 100 languages! The quality of these isn’t nearly as good as OpenAI Whisper, but they’re still useful. And they’re free (running Whisper currently costs me money).
So I adapted the plan, to provide the user with two options. The default option would extract captions directly from the video provider—which would definitely work for YouTube and might work for other sites too.
The second option would use Whisper to create a transcript and a translation, taking longer but providing results even for sites that didn’t offer their own captions.
I decided to use issue tags to trigger these two workflows: tag with “captions” to extract captions directly, tag with “whisper” to use Whisper.
The implementation
The implementation ended up being 218 lines of JavaScript-embedded-in-YAML in a GitHub Actions issue_created.yml workflow.
I used actions/github-script for it—a convenient reusable Action that provides a pre-configured set of JavaScript objects for interacting with the GitHub API.
The code isn’t hugely elegant: I’m not hugely familiar with the Node.js ecosystem so I ended up hacking around with Copilot quite a bit to figure out the patterns that would work.
It turns out captions can come back in a variety of different formats. The two most common appeared to be TTML—which uses XML, and WebVTT, a text-based format.
I decided to archive the original caption files in the GitHub repository itself, but I wanted to extract just the text and post that as the issue comment.
So I ended up building two tiny new tools: webvtt-to-json and ttml-to-json—which converted the different formats into a standard JSON format of my own invention, normalizing the captions so I could then extract the text and include it in a comment.
Hackathons tend to encourage some pretty scrappy solutions!
The results
These two issues demonstrate the final result of the tool:
- Example issue with a VK video transcribed to English using Whisper
- Example issue that extracted YouTube auto-generated English captions
That first one in particular shows quite how good the Whisper model is at handling Russian text, and translating it to English.
Adding issue templates
I added one last enhancement to the project after recording the demo video for the judges embedded above.
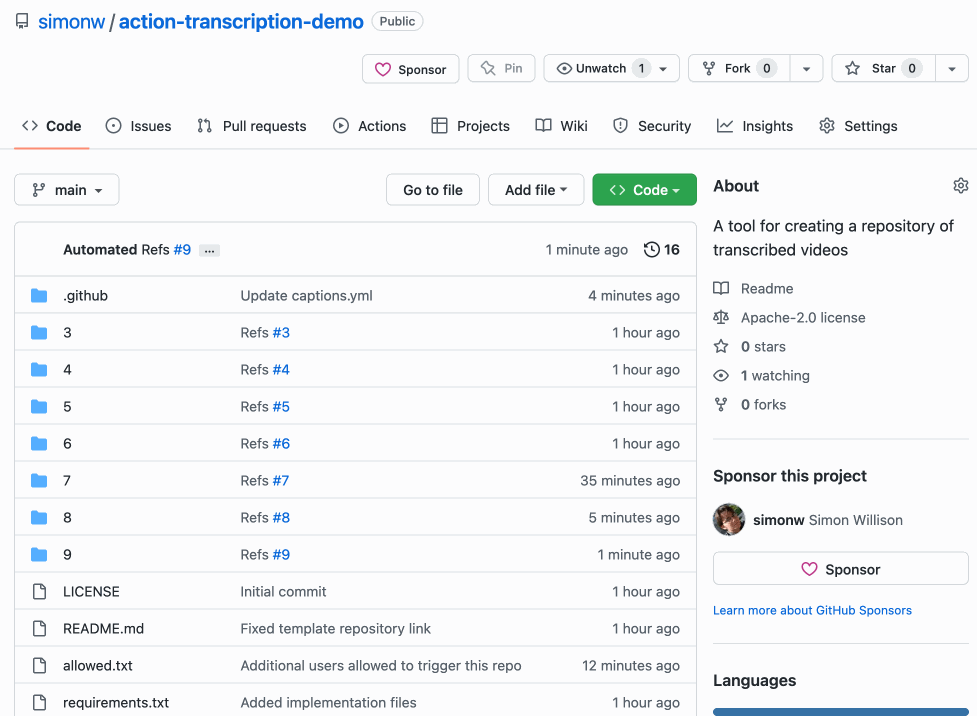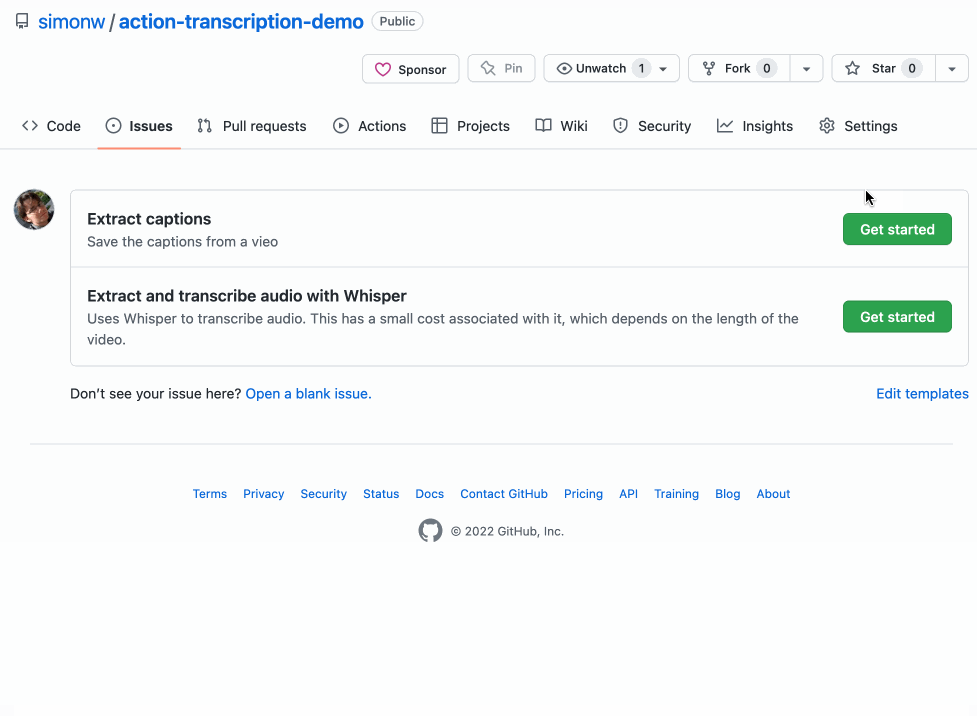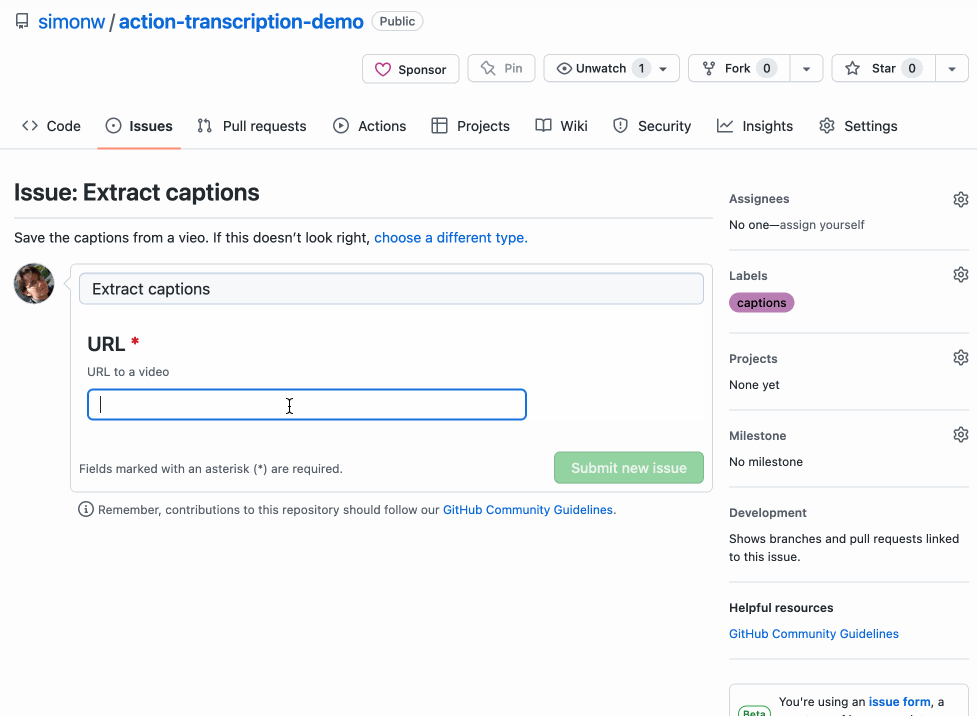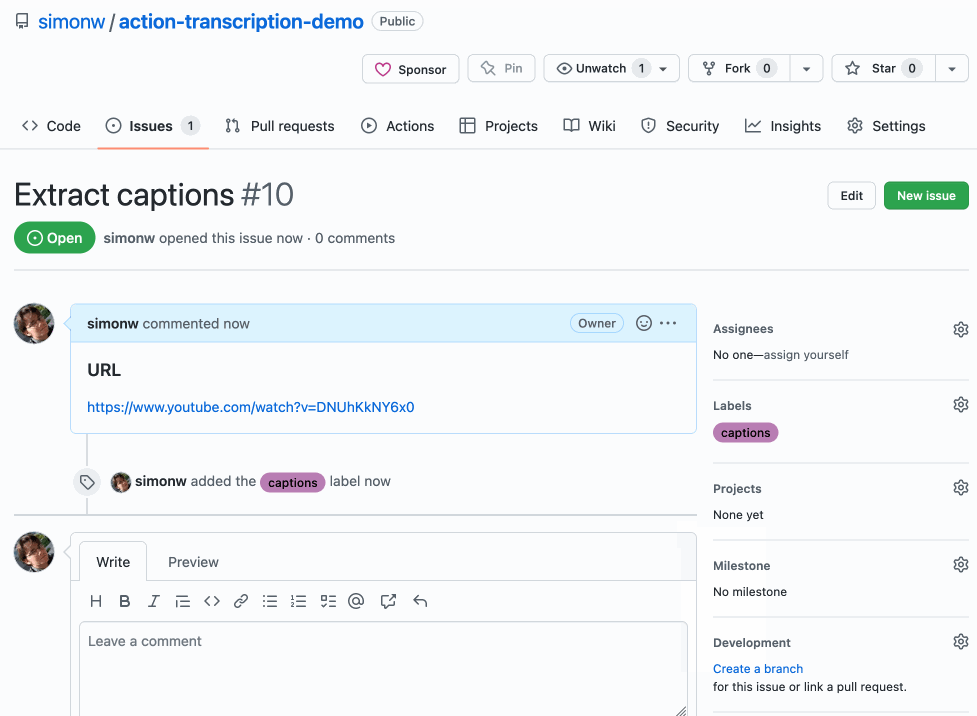
Issue templates are a new GitHub feature that let you define a form that users must fill out when they create a new issue.
Frustratingly, these only work with public repositories. I had built my hack in a private repo at first, so I was only able to explore using issue templates once I had made it public.
I created two issue templates—one for caption tasks and one for whisper tasks.
Now when a user goes to open a new issue they get to chose one of the two templates and fill in the URL as part of a form! Here’s a GIF demo showing that flow in action:
Template repositories
One last trick. I want users to be able to run this system themselves, on their own GitHub account.
I made simonw/action-transcription a template repository.
This means that any user can click a green button to get their own copy of the repository—and when they do, they’ll get their own fully configured copy of the GitHub Actions workflows too.
If they want to use Whisper they’ll need to get an API key from Replicate.com and add it to their repository’s secrets—but regular caption extraction will work fine without that.
I’ve used this technique before—I wrote about it here:
- Instantly create a GitHub repository to take screenshots of a web page
- Dynamic content for GitHub repository templates using cookiecutter and GitHub Actions
GitHub Actions as a platform
I’m pleased with how this project turned out. But I’m mainly excited about the underlying pattern. I think building tools using GitHub Actions that people can clone to their own accounts is a really promising way of developing sophisticated automated software that people can then run independently, entirely through the GitHub web interface.
I’m excited to see more tools adopt a similar pattern.
More recent articles
- Weeknotes: Llama 3, AI for Data Journalism, llm-evals and datasette-secrets - 23rd April 2024
- Options for accessing Llama 3 from the terminal using LLM - 22nd April 2024
- AI for Data Journalism: demonstrating what we can do with this stuff right now - 17th April 2024
- Three major LLM releases in 24 hours (plus weeknotes) - 10th April 2024
- Building files-to-prompt entirely using Claude 3 Opus - 8th April 2024
- Running OCR against PDFs and images directly in your browser - 30th March 2024
- llm cmd undo last git commit - a new plugin for LLM - 26th March 2024
- Building and testing C extensions for SQLite with ChatGPT Code Interpreter - 23rd March 2024
- Claude and ChatGPT for ad-hoc sidequests - 22nd March 2024
- Weeknotes: the aftermath of NICAR - 16th March 2024