Weeknotes: Datasette Lite, s3-credentials, shot-scraper, datasette-edit-templates and more
16th September 2022
Despite distractions from AI I managed to make progress on a bunch of different projects this week, including new releases of s3-credentials and shot-scraper, a new datasette-edit-templates plugin and a small but neat improvement to Datasette Lite.
Better GitHub support for Datasette Lite
Datasette Lite is Datasette running in WebAssembly. Originally intended as a cool tech demo it’s quickly becoming a key component of the wider Datasette ecosystem—just this week I saw that mySociety are using it to help people explore their WhatDoTheyKnow Authorities Dataset.
One of the neat things about Datasette Lite is that you can feed it URLs to CSV files, SQLite database files and even SQL initialization scripts and it will fetch them into your browser and serve them up inside Datasette. I wrote more about this capability in Joining CSV files in your browser using Datasette Lite.
There’s just one catch: because those URLs are fetched by JavaScript running in your browser, they need to be served from a host that sets the Access-Control-Allow-Origin: * header (see MDN). This is not an easy thing to explain to people!
The good news here is that GitHub makes every public file (and every Gist) hosted on GitHub available as static hosting with that magic header.
The bad news is that you have to know how to construct that URL! GitHub’s “raw” links redirect to that URL, but JavaScript fetch() calls can’t follow redirects if they don’t have that header—and GitHub’s redirects do not.
So you need to know that if you want to load the SQLite database file from this page on GitHub:
You first need to rewrite that URL to the following, which is served with the correct CORS header:
Asking human’s to do that by hand isn’t reasonable. So I added some code!
const githubUrl = /^https:\/\/github.com\/(.*)\/(.*)\/blob\/(.*)(\?raw=true)?$/;
function fixUrl(url) {
const matches = githubUrl.exec(url);
if (matches) {
return `https://raw.githubusercontent.com/${matches[1]}/${matches[2]}/${matches[3]}`;
}
return url;
}Fun aside: GitHub Copilot auto-completed that return statement for me, correctly guessing the URL string I needed based on the regular expression I had defined several lines earlier.
Now any time you feed Datasette Lite a URL, if it’s a GitHub page it will automatically rewrite it to the CORS-enabled equivalent on the raw.githubusercontent.com domain.
Some examples:
- https://lite.datasette.io/?url=https://github.com/lerocha/chinook-database/blob/master/ChinookDatabase/DataSources/Chinook_Sqlite.sqlite—that Chinook SQLite database example (from here)
- https://lite.datasette.io/?csv=https://github.com/simonw/covid-19-datasette/blob/6294ade30843bfd76f2d82641a8df76d8885effa/us_census_state_populations_2019.csv—US censes populations by state, from my simonw/covid-19-datasette repo
datasette-edit-templates
I started working on this plugin a couple of years ago but didn’t get it working. This week I finally closed the initial issue and shipped a first alpha release.
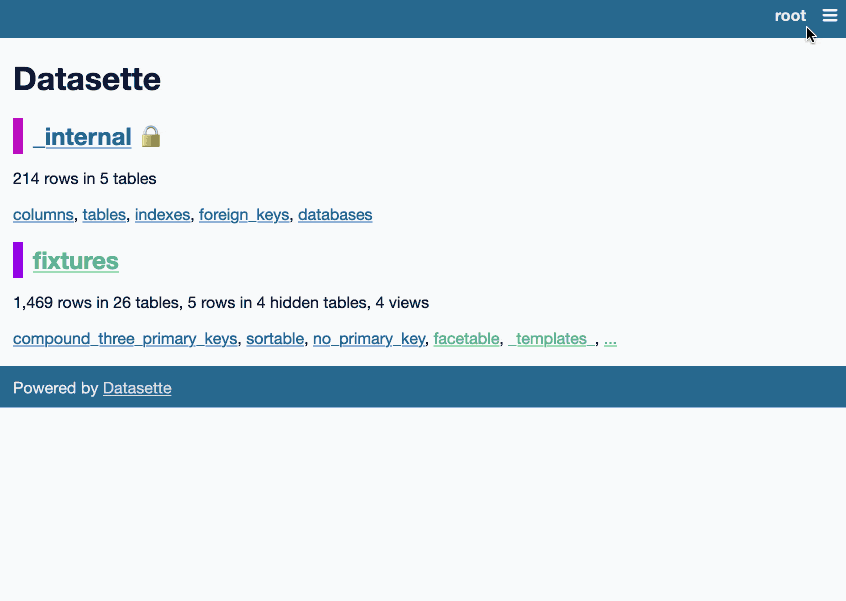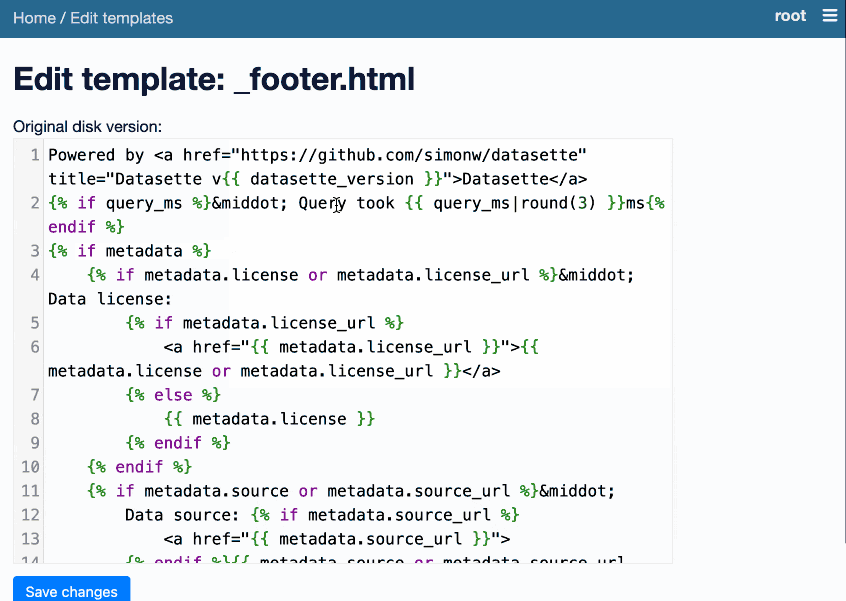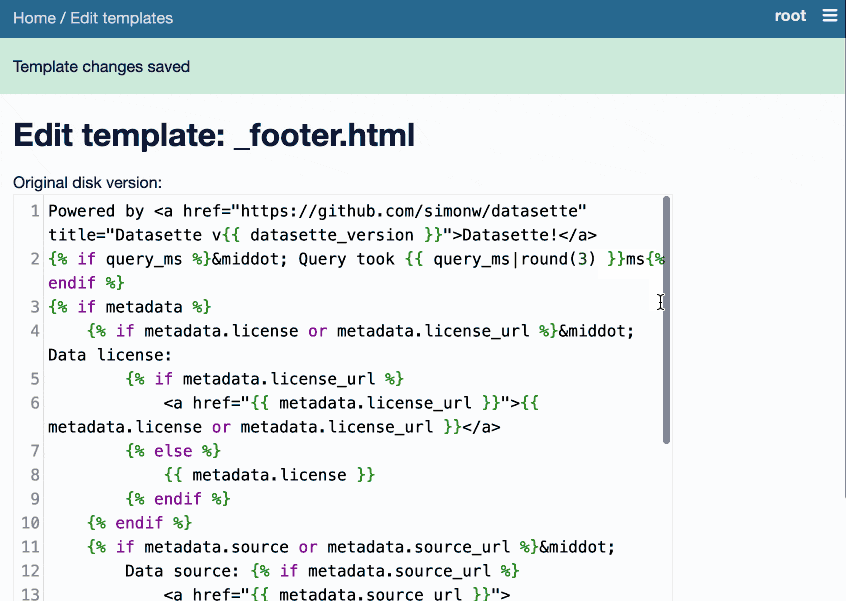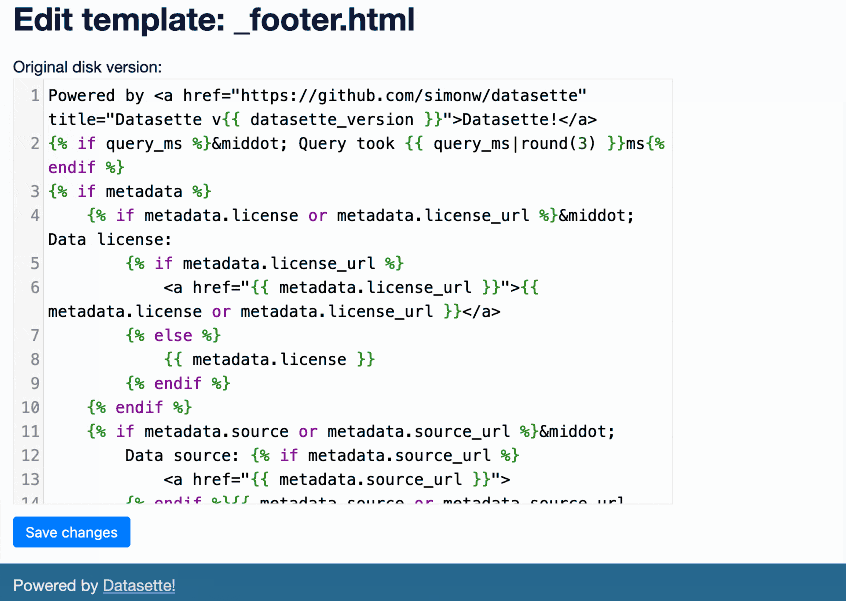
It’s pretty fun. On first launch it creates a _templates_ table in your database. Then it allows the root user (run datasette data.db --root and click the link to sign in as root) to edit Datasette’s default set of Jinja templates, writing their changes to that new table.
Datasette uses those templates straight away. It turns the whole of Datasette into an interface for editing itself.
Here’s an animated demo showing the plugin in action:
The implementation is currently a bit gnarly, but I’ve filed an issue in Datasette core to help clear some of it up.
s3-credentials get-objects and put-objects
I built s3-credentials to solve my number one frustration with AWS S3: the surprising level of complexity involved in issuing IAM credentials that could only access a specific S3 bucket. I introduced it in s3-credentials: a tool for creating credentials for S3 buckets.
Once you’ve created credentials, you need to be able to do stuff with them. I find the default AWS CLI tools relatively unintuitive, so s3-credentials has continued to grow other commands as and when I feel the need for them.
The latest version, 0.14, adds two more: get-objects and put-objects.
These let you do things like this:
s3-credentials get-objects my-bucket -p "*.txt" -p "static/*.css"
This downloads every key in my-bucket with a name that matches either of those patterns.
s3-credentials put-objects my-bucket one.txt ../other-directory
This uploads one.txt and the whole other-directory folder with all of its contents.
As with most of my projects, the GitHub issues threads for each of these include a blow-by-blow account of how I finalized their design—#68 for put-objects and #78 for get-objects.
shot-scraper --log-requests
shot-scraper is my tool for automating screenshots, built on top of Playwright.
Its latest feature was inspired by Datasette Lite.
I have an ongoing ambition to get Datasette Lite to work entirely offline, using Service Workers.
The first step is to get it to work without loading external resources—it currently hits PyPI and a separate CDN multiple times to download wheels every time you load the application.
To do that, I need a reliable list of all of the assets that it’s fetching.
Wouldn’t it be handy If I could run a command and get a list of those resources?
The following command now does exactly that:
shot-scraper https://lite.datasette.io/ \
--wait-for 'document.querySelector("h2")' \
--log-requests requests.log
Here’ the --wait-for is needed to ensure shot-scraper doesn’t terminate until the application has fully loaded—detected by waiting for a <h2> element to be added to the page.
The --log-requests bit is a new feature in shot-scraper 0.15: it logs out a newline-delimited JSON file with details of all of the resources fetched during the run. That file starts like this:
{"method": "GET", "url": "https://lite.datasette.io/", "size": 10516, "timing": {...}}
{"method": "GET", "url": "https://plausible.io/js/script.manual.js", "size": 1005, "timing": {...}}
{"method": "GET", "url": "https://latest.datasette.io/-/static/app.css?cead5a", "size": 16230, "timing": {...}}
{"method": "GET", "url": "https://lite.datasette.io/webworker.js", "size": 4875, "timing": {...}}
{"method": "GET", "url": "https://cdn.jsdelivr.net/pyodide/v0.20.0/full/pyodide.js", "size": null, "timing": {...}}
This is already pretty useful... but wouldn’t it be more useful if I could explore that data in Datasette?
That’s what this recipe does:
shot-scraper https://lite.datasette.io/ \
--wait-for 'document.querySelector("h2")' \
--log-requests - | \
sqlite-utils insert /tmp/datasette-lite.db log - --flatten --nl
It’s piping the newline-delimited JSON to sqlite-utils insert which then inserts it, using the --flatten option to turn that nested timing object into a flat set of columns.
I decided to share it by turning it into a SQL dump and publishing that to this Gist. I did that using the sqlite-utils memory command to convert it to a SQL dump like so:
shot-scraper https://lite.datasette.io/ \
--wait-for 'document.querySelector("h2")' \
--log-requests - | \
sqlite-utils memory stdin:nl --flatten --dump > dump.sql
stdin:nl means “read from standard input and treat that as newline-delimited JSON”. Then I run a select * command and use --dump to output that to dump.sql, which I pasted into a new Gist.
So now I can open the result in Datasette Lite!
Datasette on Sandstorm
Sandstorm is “an open source platform for self-hosting web apps”. You can think of it as an easy to use UI over a Docker-like container platform—once you’ve installed it on a server you can use it to manage and install applications that have been bundled for it.
Jacob Weisz has been doing exactly that for Datasette. The result is Datasette in the Sandstorm App Market.
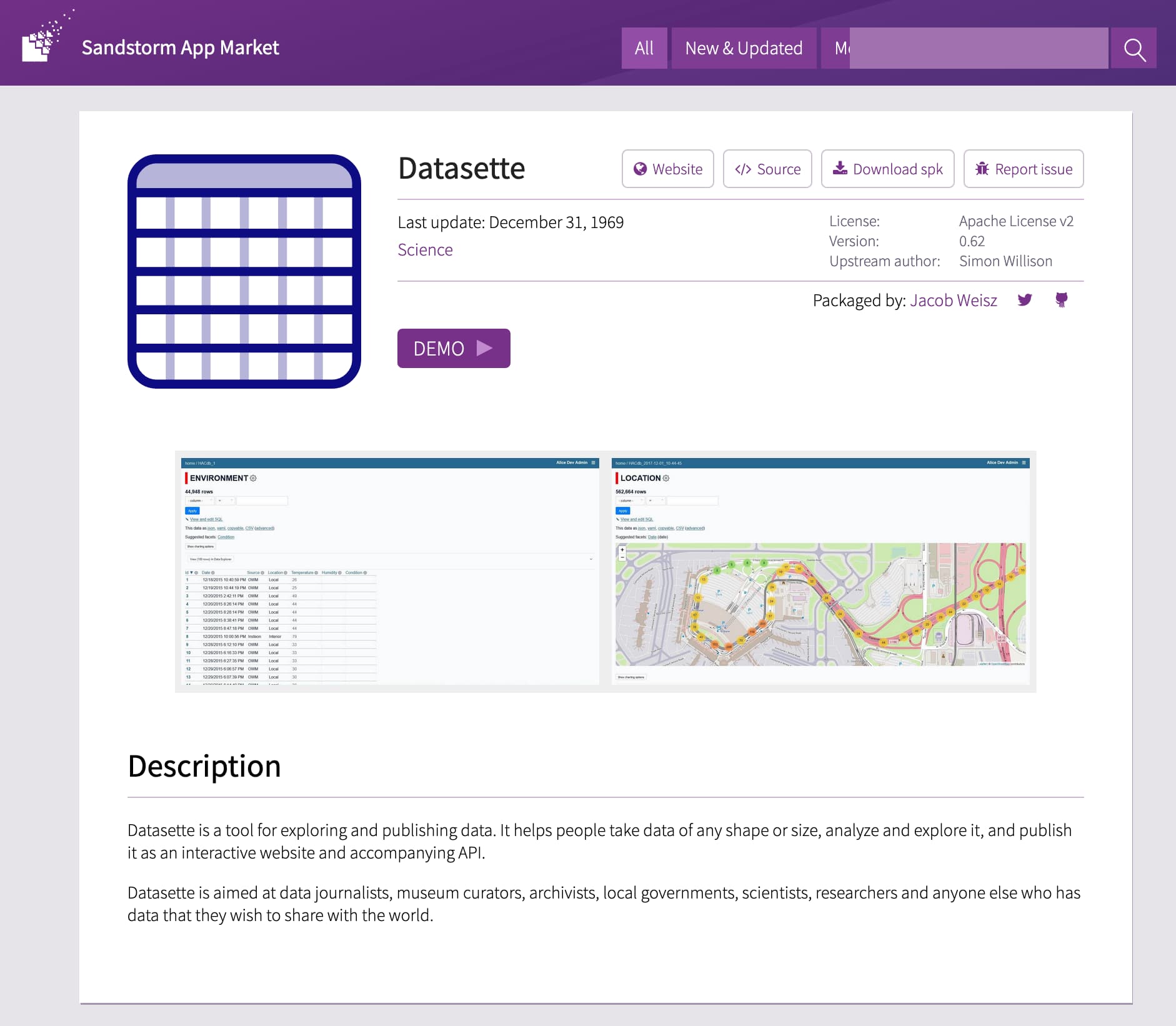
You can see how it works in the ocdtrekkie/datasette-sandstorm repo. I helped out by building a small datasette-sandstorm-support plugin to show how permissions and authentication can work against Sandstorm’s custom HTTP headers.
Releases this week
-
s3-credentials: 0.14—(15 releases total)—2022-09-15
A tool for creating credentials for accessing S3 buckets -
shot-scraper: 0.16—(21 releases total)—2022-09-15
A command-line utility for taking automated screenshots of websites -
datasette-edit-templates: 0.1a0—2022-09-14
Plugin allowing Datasette templates to be edited within Datasette -
datasette-sandstorm-support: 0.1—2022-09-14
Authentication and permissions for Datasette on Sandstorm -
datasette-upload-dbs: 0.1.2—(3 releases total)—2022-09-09
Upload SQLite database files to Datasette -
datasette-upload-csvs: 0.8.2—(13 releases total)—2022-09-08
Datasette plugin for uploading CSV files and converting them to database tables
TIL this week
More recent articles
- Three major LLM releases in 24 hours (plus weeknotes) - 10th April 2024
- Building files-to-prompt entirely using Claude 3 Opus - 8th April 2024
- Running OCR against PDFs and images directly in your browser - 30th March 2024
- llm cmd undo last git commit - a new plugin for LLM - 26th March 2024
- Building and testing C extensions for SQLite with ChatGPT Code Interpreter - 23rd March 2024
- Claude and ChatGPT for ad-hoc sidequests - 22nd March 2024
- Weeknotes: the aftermath of NICAR - 16th March 2024
- The GPT-4 barrier has finally been broken - 8th March 2024
- Prompt injection and jailbreaking are not the same thing - 5th March 2024
- Interesting ideas in Observable Framework - 3rd March 2024